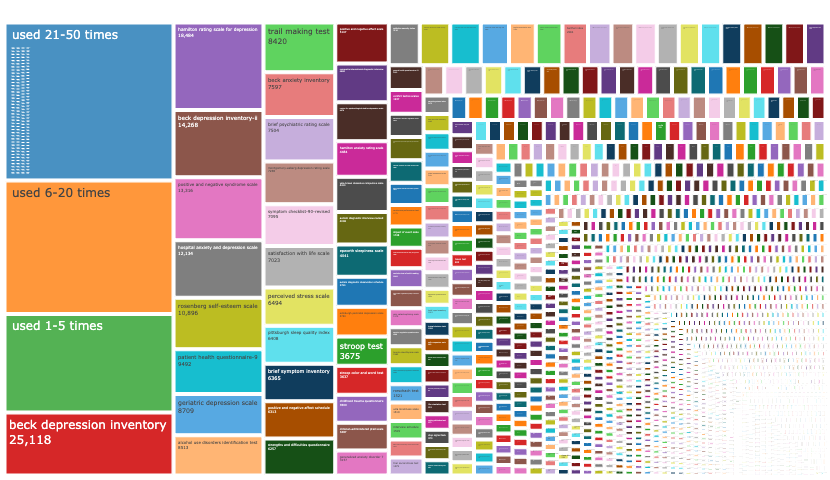
Recently, Malte, Taym, Ian and I wrote a short commentary paper on the toothbrush problem for measures in psychology: Everybody…
Recently, Malte, Taym, Ian and I wrote a short commentary paper on the toothbrush problem for measures in psychology: Everybody…

This post is second in a series. The first part is Why I placed a bounty on my own research,…

In the current system of pre-publication peer review, which papers are scrutinized most thoroughly? In this blog post, I argue…
Accounting for mistakes in my scientific work and announcing a bug bounty program. A story of few papers and many…
Next, we tested whether studies with bigger sample sizes are cited more. More and more, it’s looking as if citations…
I looked at citations as an indicator of research quality by dusting off two analyses that I did quickly a…

Here’s a little-told story about the origins of Google. Larry Page and Sergey Brin were inspired by research in scientometrics on…

Someone recently told me I was wrong about something. You can read the exchange here (Woodley et al., our reply).[1]minus…
This post is a joint effort from all of us at the 100% CI. There is a subreddit for crazy…

Estimated reading time: ~6 minutes In the debate around open data, I’m missing voices from people working with public or…