This blog post resulted from a draft that was supposed to become a proper article at some point. Michael Dufner and Tailcalled both worked on the draft and contributed important ideas. But, as so often, we couldn’t find a satisfying conclusion, so here we are. Michael and Tailcalled are both to be credited for the bright side of this blog post but exonerated from any responsibility for its dark sides (including all bad jokes and also the discussion section).
There is a peculiar pattern in psychology: researchers discover that their construct of interest can be “disentangled” into two subfactors. Those two subfactors show a small to medium positive correlation with each other, but their associations with other variables diverge. One usually seems to be adaptive, in the sense that it is positively associated with good things (well-being, social functioning,…). That’s the bright side of the construct. The other one seems to be maladaptive in the sense that it is negatively associated with good things and positively associated with bad things. That’s the dark side of the construct. Some examples:
Personality researchers distinguish between different subfactors of narcissism. There are many different models here, and to pick one example, Back et al. (2013) suggest the two subfactors narcissistic admiration—a tendency to search for social success by means of self-promotion (e.g., “I will someday be famous”)—and narcissistic rivarly—a tendency to prevent social failure by means of self-defense (“I enjoy it when another person is inferior to me”). While these two factors show a medium to large positive intercorrelation, their associations with social success diverge: admiration is associated with increasing popularity over time; rivalry is associated with decreasing popularity (Leckelt et al., 2015).
Enns, Cox and Clara (2002) distinguish between adaptive perfectionism (e.g., “I strive to be as perfect as can be”) and maladaptive perfectionism (e.g., “If I fail at work/school, I am a failure as a person”). While the two factors show a medium to large positive intercorrelation, only maladaptive perfectionism shows a large positive correlation with depression proneness. If adaptive perfectionism is linked to depression proneness at all, the correlation is negative.
Krasko, Schweitzer and Luhmann (2021) suggest two subfactors for people’s happiness goal orientations, which are interindividual differences in the extent to which people value and pursue happiness. Happiness-related strivings refers to a tendency to actively move toward happiness (“I often overcome challenges to become happy”); happiness-related concerns refers to worries about one’s happiness (“I am worried that I might be unhappy in the future”). The two factors are moderately correlated. Happiness strivings are associated with high positivity and successful mood regulation strategies; happiness concerns are associated with anxiety and poor regulation strategies.
And for a change of pace, one from health research: Barthels, Barrada and Roncero (2019) suggest two subfactors of eating styles related to orthorexia. Healthy orthorexia is characterized by seeking out healthy foods (“I feel good when I eat healthy food”), orthorexia nervosa in contrast is characterized by negative affect related to food (“Thoughts about healthy eating do not let me concentrate on other tasks”). These two factors show a medium intercorrelation. Healthy orthorexia is associated with increased positive affect, whereas orthorexia nervosa is associated with increased negative affect.
More constructs that may fit the bill:
- affiliative motive (“bright positive side” and “dark negative side,” see here)
- envy (“benign” and “malicious,” see here)
- passion (“harmonious” and “obsessive,” see here)
- pride (“authentic” and “hubristic,” see here)
- rumination (“positive” and “negative,” see here)
- self-monitoring (“acquisitive” and “protective,” see here).
How come? One explanation is that there is some overarching law of personality. In my forthcoming book, “The Yin and Yang of Personality,” I will explain… Just kidding.
Such “bright side/dark side” constructs can be generated if we (intentionally or unintentionally) pick items that combine aspects of one construct of interest (e.g., perfectionism) and a second potentially unrelated construct (e.g., emotional stability) which overall tends to correlate with things that are considered desirable (or, alternatively, undesirable; the signs of the association don’t matter). In this scenario, the standard data analytic approach will result in two correlated factors, one being “adaptive,” the other one being “maladaptive.” The thing is, those factors don’t necessarily reflect the reality of the factors that generated the data.

First, I will present simulated data to explain what’s going on on the statistical side of things. Then, I will present an empirical example to show how the way we slice the construct may affect subsequent substantive conclusions. In the discussion, I will suggest different ways to think about what’s going on with all those bright/dark side constructs.[1]Lastly, I will demonstrate that academic signposting (explicitly telling readers what comes next) is a bad writing habit that can only be justified if there is a mismatch between readers expectations and reality (“It’s more of an article than a blog post”).
Exaggerated Toy Example: Chocolate Obsession versus ChocOlate Appreciation (COCOA)
Let’s assume we were interested in assessing interindividual differences in people’s relationship with chocolate. How much people like chocolate may be deemed a neutral trait: Some people like chocolate more than others, and there is no a priori reason to assume that they differ much in terms of psychological adjustment (except for some edge cases, looking at you 100%-cocoa-no-added-sugar sickos).
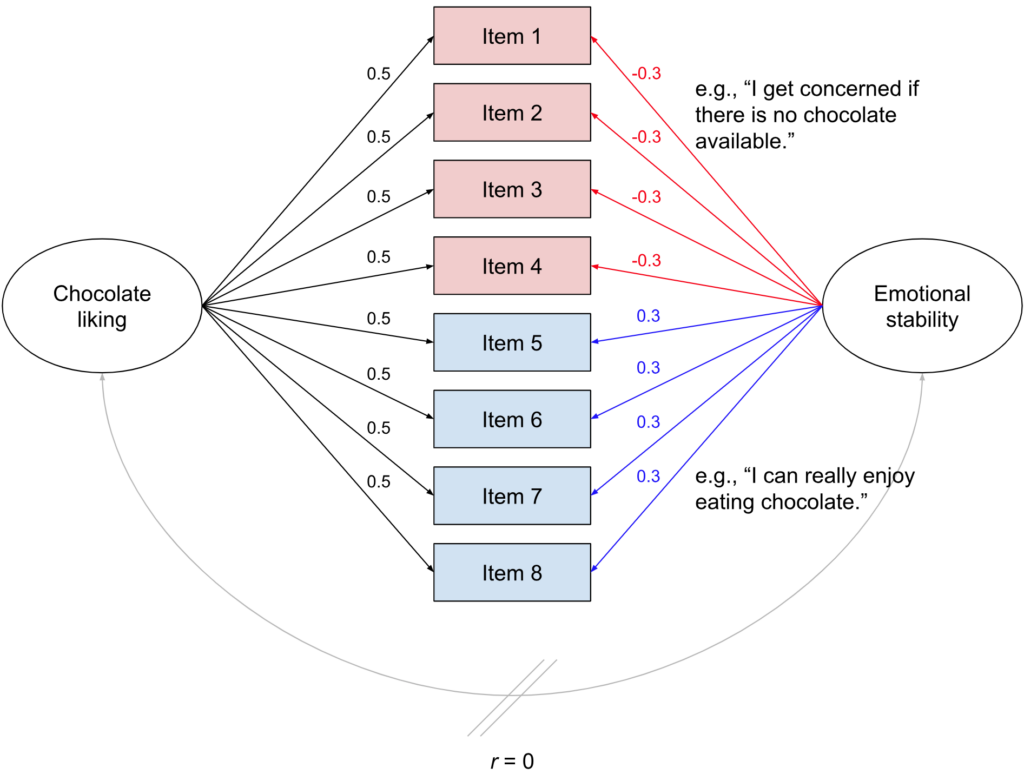
To develop a self-report measure of chocolate liking, we generate eight items. But here comes the twist: We select our items so that four of them not only reflect chocolate liking but also high levels of emotional stability. Possible items could be “As long as chocolate exists, I can see the bright side of life”; “I can really enjoy eating chocolate”; “When I eat chocolate, I feel great”; and “A good bar of chocolate makes my day.” For the other four items, we go for phrasings that not only reflect chocolate liking, but also low levels of emotional stability. Possible items could be “I get concerned if there is no chocolate available”; “A lack of chocolate makes me very sad”; “Sometimes I worry I might run out of chocolate”; “Chocolate helps me to deal with the high amount of stress in my life.” Why, you may be wondering, would you add such mix-ins to your chocolate? We will discuss that later, so just stick with me for now.
In this thought experiment observational survey study, we know the underlying process that generates people’s responses to these items, see Fig. 2. Responses are generated by two underlying latent factors, chocolate liking and emotional stability. These factors are uncorrelated.[2]Ruben maintains that this is not the case and that there should be a small positive correlation between the two. Allowing for such a correlation would not change the general pattern and our next example will include for a correlation between the two underlying factors, so all the Bridget Jones lovers out there can mentally insert r = .2 here. Chocolate liking loads on all items to the same extent, but emotional stability loads negatively on half of the items and positively on the second half of items.
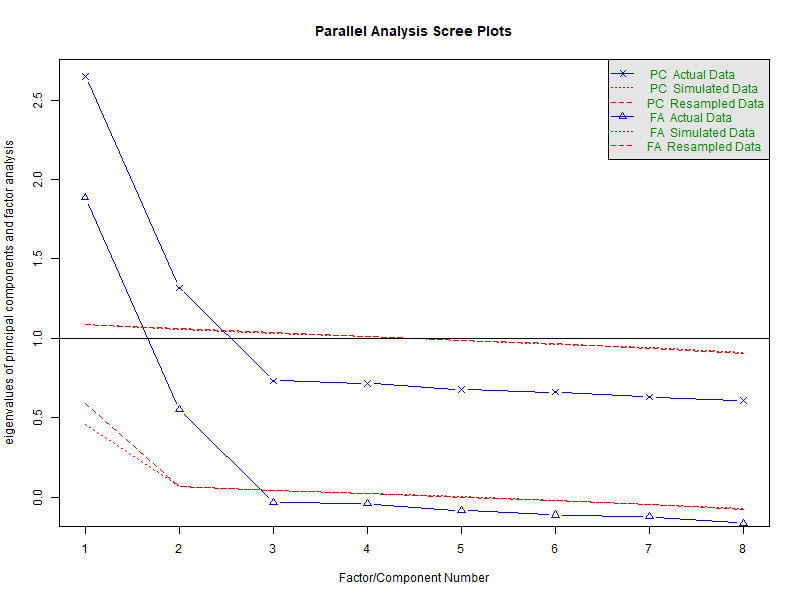
Now, let us collect data from 2,000 fictitious respondents and analyze it following standard practices. In a first step, we perform an exploratory factor analysis (EFA) with the help of the R package psych. For this purpose, we first need to determine how many factors to extract. There are different ways to inform this decision, but here, fortunately, they all converge anyway (Fig. 3): We definitely should extract two factors.
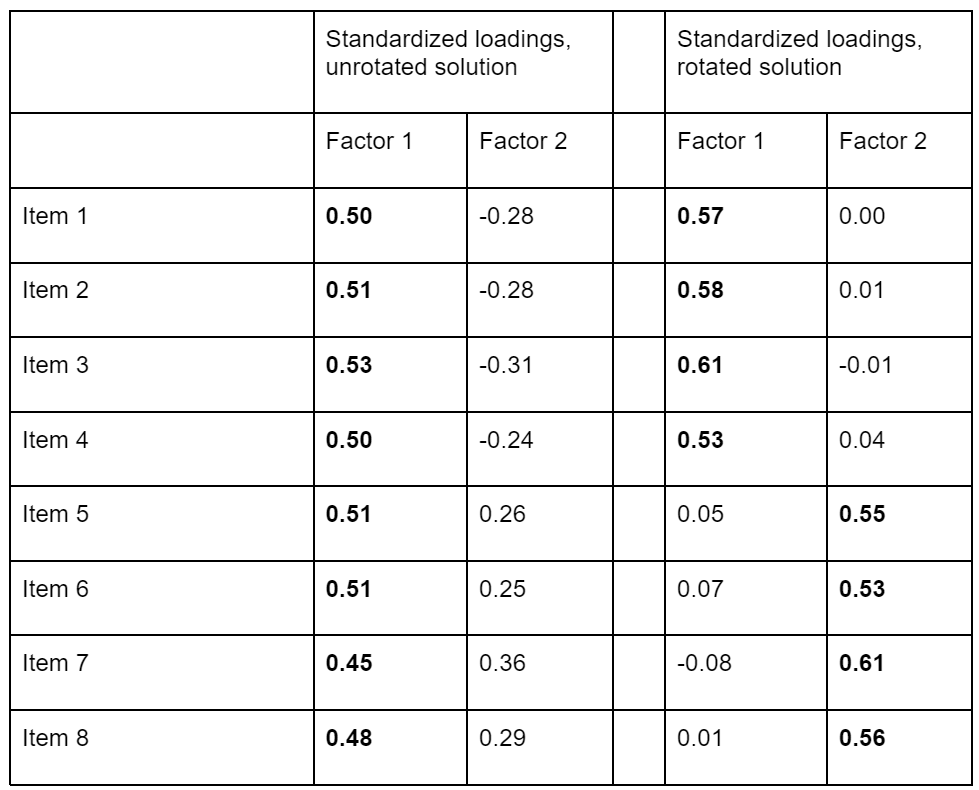
If we move on and extract two factors, psych will automatically return a rotated solution, and even if you use software that doesn’t rotate by default, you’re probably going to rotate anyway. However, let’s first take a look at the unrotated solution in Table 1.
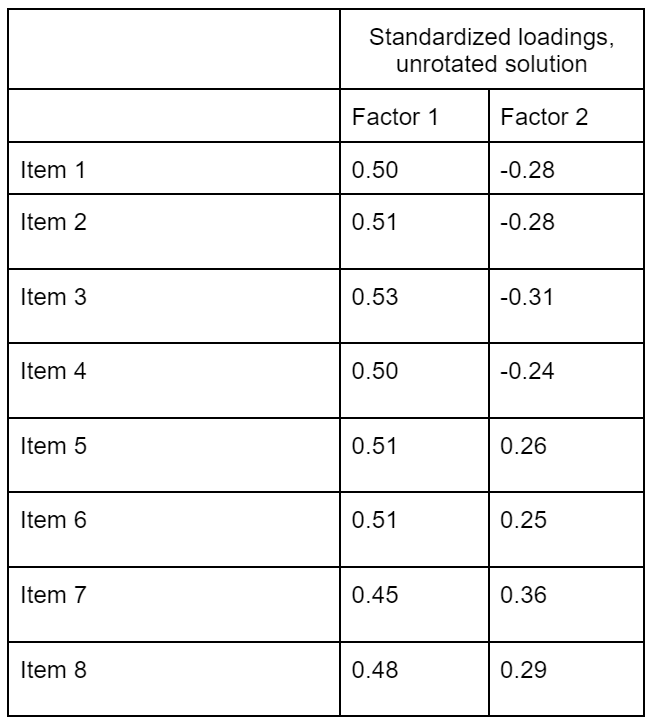
If you compare those numbers to Fig. 2, you can see that they reflect the underlying data-generating mechanism well. There is one factor that loads quite strongly on all items (chocolate liking), and there is a second factor (emotional stability) with somewhat weaker absolute loadings, half of which have a positive sign and half of which have a negative sign. So far, so good.
But results from exploratory factor analysis are usually rotated to improve interpretability. In the unrotated version, the first factor will “soak up” as much explanatory power as possible and have many high loadings; rotation distributes the explanatory power of the factors more evenly and we often aim for a so-called simple structure in which each item “belongs” to a single factor. So, let’s rotate those factors!

We are going to use the default setting (oblimin rotation), although which of the standard rotations you pick here won’t make a big difference.
As we can see in Table 2, newly added columns to the right, we still have two factors—the rotation doesn’t really “change” the factors, it only rotates them in the eight-dimensional plane defined by the responses to all eight items. If you struggle to visualize this, for an imperfect approximation, stretch out your fingers like in Fig. 4 and then vigorously twist your hand around.[3]This corresponds to a situation in which you use three orthogonal factors (your three fingers) to explain the space around you. Given that the space around you has three dimensions to begin with, your hand model is perfect. Hands! Wow.
But the pattern of loadings now looks completely different. The first factor loads on the first four items and the second factor loads on the second four items, all cross-loadings are close to zero. The resulting factors are correlated, r = .49.
What happened here? First, the unrotated factor analysis solution recovered the data-generating mechanism that we actually plugged into our analysis: one factor that strongly loads onto all items, and then a second factor that loads positively onto half of the items and negatively onto the other half.[4] That the unrotated solution corresponds to the truth is only because of the data-generating mechanism we simulated. If it always worked like that, this blog post would be a lot shorter. But then rotation led to a “simpler” version in which only one factor loads onto each of the items. From a “purely statistical” perspective, the rotation makes no difference whatsoever—any rotation of the solution is observationally equivalent, which means that it fits onto the observed data equally well. Conventionally, the rotated solution is reported. It’s just like in the song: oblimin, oblada, life goes on, brah.
But we can see that if we aim to give a substantive interpretation to these numbers, rotation makes all the difference. The unrotated version tells us that there are two independent factors which one could, for example, label “chocolate liking” and “emotional stability.” The rotated version tells us that there are two correlated factors. The first one may be labeled “chocolate obsession” (“I get concerned if there is no chocolate available”; “A lack of chocolate makes me very sad”; “Sometimes I worry I might run out of chocolate”; “Chocolate helps me to deal with the high amount of stress in my life”), the second may be labeled “chocolate appreciation” (“As long as chocolate exists, I can see the bright side of life”; “I can really enjoy eating chocolate”; “When I eat chocolate, I feel great”; “A good bar of chocolate makes my day”): The bright and dark side of liking chocolate.
We know that the Chocolate Obsession/ChocOlate Appreciation (COCOA) structure did not actually generate the data. Maybe its emergence from the data is a quirk of exploratory factor analysis? So let’s check whether confirmatory factor analysis would be able to discard the COCOA model.[5] We should do this with new data; we could do this with the data underlying the EFA (to cite Anne: “CFA confirms the factor structure you found in an EFA in the same dataset? d’uh”). Luckily, it won’t make a difference for the bright/dark side thing because it is not a matter of sampling variability. In any case, we specify a model with two factors which are allowed to correlate. One of the factors is measured with the first four items; the other one is measured with the second four items, as suggested by our exploratory factor analysis after rotation.
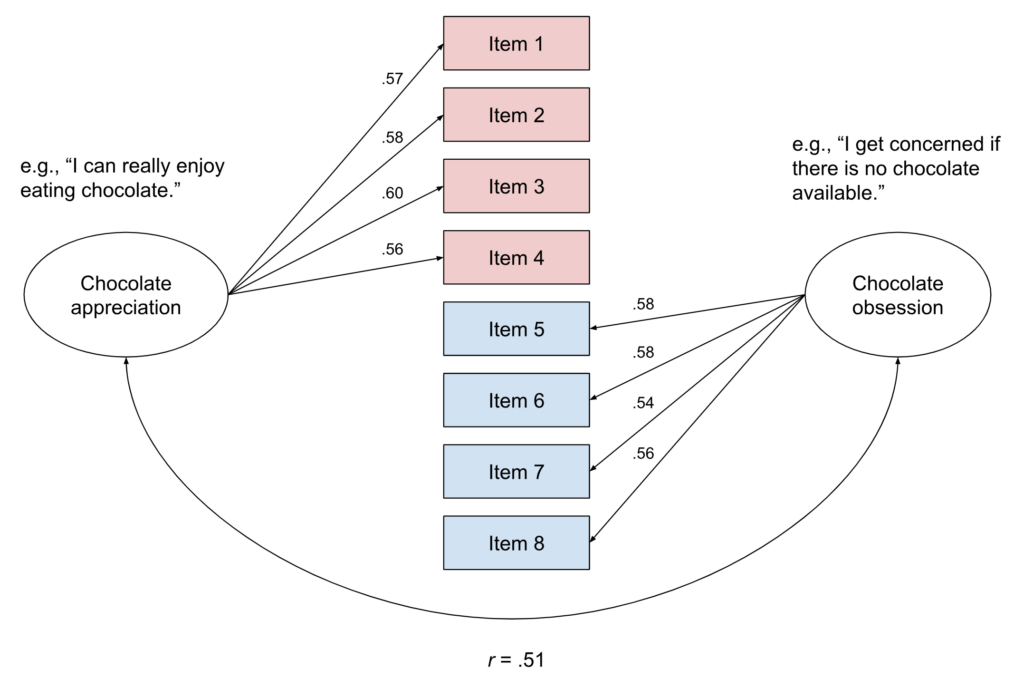
This model fits the data well according to conventional criteria (CFI = .99, RMSEA = .02, SRMR = .02). In fact, the data didn’t really have any chance to reject the model because the true data-generating model (Fig. 2) is observationally equivalent to the bright/dark side version. That means that both models predict the same empirical data (the same variance-covariance matrix of the item responses); both models will fit the data equally well.
With this additional “confirmation” of the COCOA model, we may want to look for further validation by investigating how the two factors are associated with other constructs. For example, we may want to explore how these two factors are related to depressiveness. We find that chocolate appreciation is associated with reduced depressiveness (r = -.29); chocolate obsession is associated with increased depressiveness (r = .31). This pattern further supports the idea that there are two distinguishable constructs, and the difference matters from a substantive perspective. Chocolate obsession is worrying from a mental health perspective; chocolate appreciation in contrast may even be a protective factor. More research is needed.
What happened here? We simulated depressiveness as a random variable that is negatively affected by emotional stability. Since chocolate appreciation mixes chocolate liking with high emotional stability, it will be negatively correlated with depressiveness. And since chocolate obsession mixes chocolate liking with low emotional stability, it will be positively correlated with depressiveness. In fact, the whole chocolate thing doesn’t have anything to do with the correlation with depressiveness.[6] Or just a tiny bit, for proponents of the Bridget Jones hypothesis.
This toy example assumes a very simple and exaggerated data-generating mechanism, but it captures a crucial feature of both exploratory and confirmatory factor analysis. These analyses do not necessarily uncover the latent factor structure that actually underlies the data. Another way to put this is to say “correlation does not imply causation.” As an input, factor analysis takes the associations between the items. As an output, it returns a structure that may have caused the item responses. But a pattern of correlations is always compatible with multiple causal stories, so different factor models (and alternatives, including network models) will fit the data equally well.
Real Data Example: Happiness Goal Orientations and their Associations with Well-Being
Illustrating a point with data tailored for the purpose always feels a bit like cheating, so let’s look at some real data. As mentioned in the introduction, Krasko, Schweitzer, and Luhmann (2021) developed a questionnaire that assesses two aspects of happiness goal orientations, happiness-related strivings (the propensity to move actively toward happiness) and happiness-related concerns (the propensity to worry about threats to happiness). Their article is great, it’s trying to make sense of previous contradictory findings and takes into account multiple possible model specifications. And Krasko et al. made the present re-analysis possible by openly sharing their data and code and providing excellent documentation. In other words, it’s the type of article that contributes to my researcher happiness goals.
A central substantive question in this literature is whether striving for happiness is good (or bad) for one’s happiness, and to demonstrate how the bright/dark side factor structure may affect conclusions about that, we will model multiple constructs simultaneously:
- the independent variable(s) of interest: happiness-goal orientations (5 items measuring strivings, 5 items measuring concerns)
- the dependent variable of interest: life satisfaction (5 items, the Satisfaction With Life Scale)
- the potential third-variable offender: neuroticism (3 items from the Big Five Inventory 2), which in personality lingo is the same as reverse-coded emotional stability.
Two Factors: Strivings and Concerns
First, we fit a model that includes the two happiness goal orientation factors (Fig. 6): happiness strivings (“bright side”) and happiness concerns (“dark side”). The model fit is okay-ish (definitely better than many model fits in the literature which I have seen described as good), so let’s not worry about that too much. The correlation between happiness-related concerns and happiness-related strivings is quite low (r = .14). In contrast, the correlation between happiness-related concerns and neuroticism is really strong (r = .81). As would be expected, there is a strong negative correlation between neuroticism and life satisfaction (r = -.66). And, in line with the findings reported by Krasko et al., strivings are positively associated with life satisfaction (r = .22), whereas concerns are negatively associated (r = -.46).
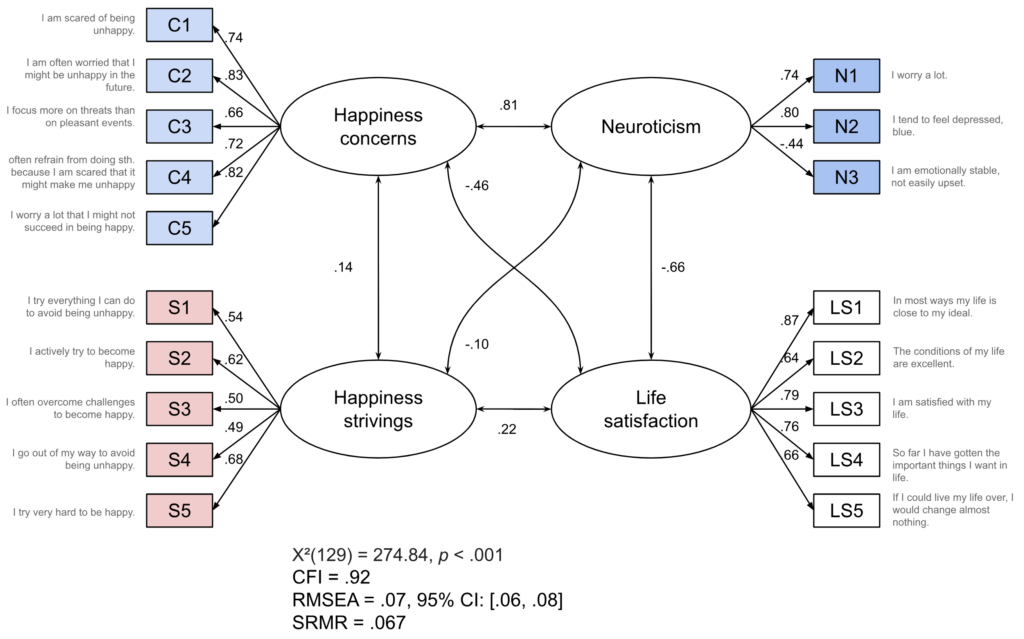
We may want to check whether happiness goal orientations predict life satisfaction beyond neuroticism, using this conceptualization of the factors. We can do that by taking the model from Fig. 6 but instead of allowing all factors to correlate, we include directed arrows that point from happiness concerns, happiness strivings, and neuroticism to life satisfaction.
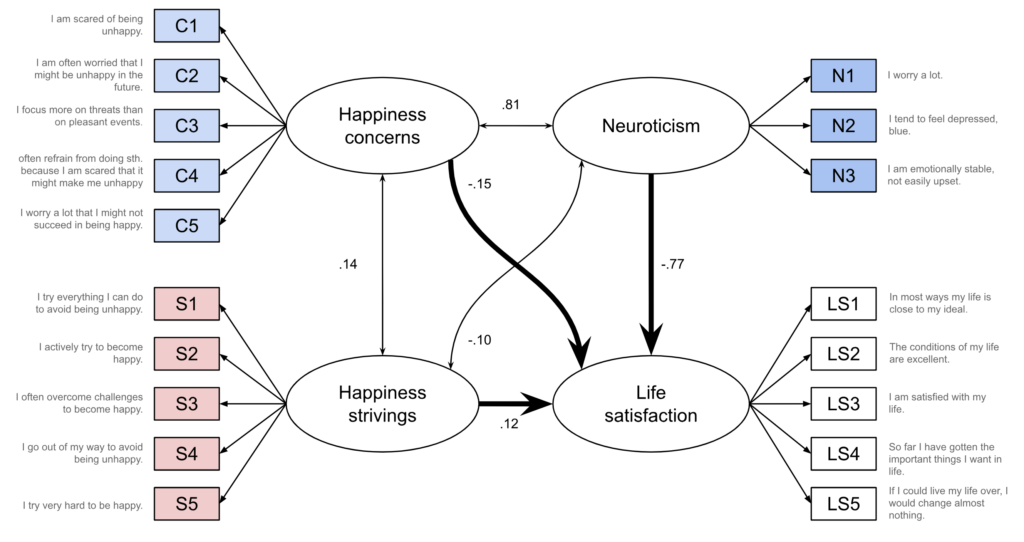
In this analysis, neuroticism ends up with a very large negative coefficient (b = -.77, p = .001). Both happiness goal orientations have smaller coefficients but fail to reach statistical significance; concerns: b = -.15, p = .436, strivings: b = .12, p = .163. Thus, assuming that neuroticism is causally prior to happiness goal orientations (and to life satisfaction) and thus a confounder, one may conclude that the observed correlations—the negative one for happiness concerns and the positive one for happiness strivings—are at least partly, if not mostly, due to confounding.
One Factor: General Happiness Goal Orientation
As we have seen above, the correlation between happiness concerns and neuroticism is quite high (r = .81). So let’s consider a model in which there is actually only a single happiness goal orientation factor. Additionally, neuroticism is allowed to load onto all items that were previously part of the happiness concerns factor (Fig. 8). You may notice that this is a slightly different structure than the chocolate obsession/chocolate appreciation data-generating mechanism, in which the second factor loaded onto all items.[7]If we wanted to fit that type of structure, the model would not be identified (unless we incorporated some additional constraints, such as the equality of certain loadings). But you don’t need the full-blown “second factor affects every single item either positively or negatively” structure to induce a bright/dark side structure, and maybe that’s the more realistic scenario to begin with: some but not all items are affected by a second factor. This has the added benefit that the correlations with other constructs are not just going to be mirror images of each other (which would start to look suspicious at some point), even if it is less pleasingly symmetrical. The model fit is now slightly worse but still very much in the same ballpark.
Neuroticism is still negatively correlated with life satisfaction (r = -.60) while the happiness goal orientation factor is positively correlated with life satisfaction (r = .26). Furthermore, there is a slight negative correlation between neuroticism and happiness goal orientation (r = -.18). If we look at the loadings, we can see that the happiness goal orientation factor loads more strongly onto the striving items (loadings between .50 and .65) than onto the concern items (loadings between .11 and .33). The latter are more strongly determined by neuroticism (loadings between .69 and .82). We may take this as a sign that maybe the happiness concerns items don’t really fit the construct of happiness goal orientation to begin with, but note that in this model, the meaning of neuroticism will have shifted because in the end, the content of the factor is determined by the indicators—and we have just added a bunch of happiness concerns to the construct of neuroticism.
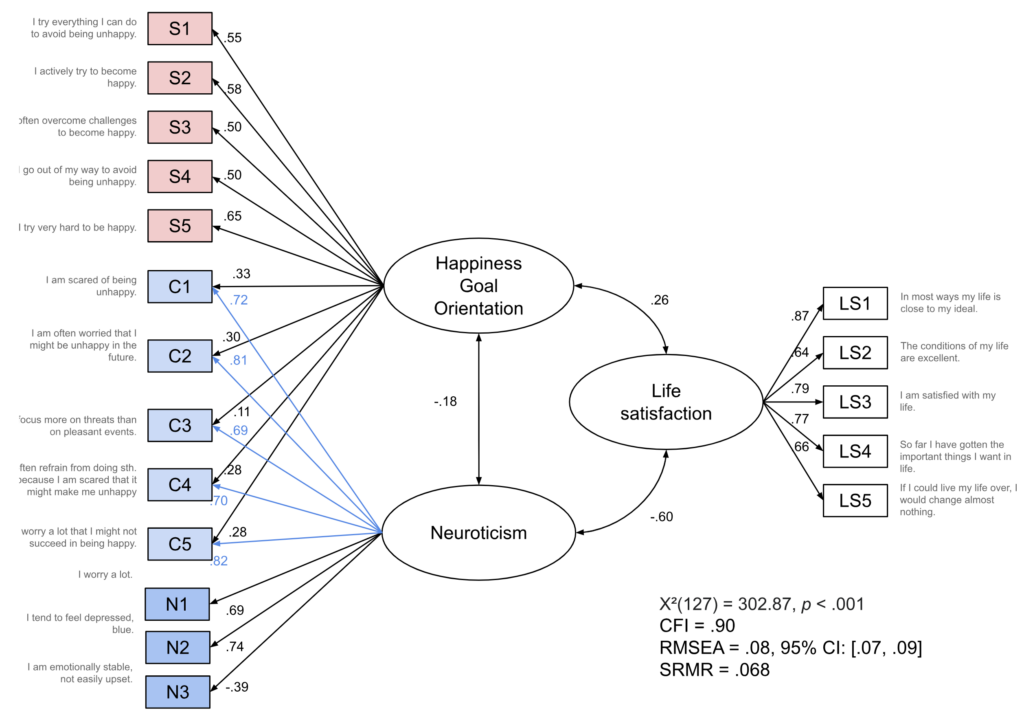
Again we may want to check whether happiness goal orientation predicts life satisfaction beyond neuroticism, using this alternative single-factor conceptualization. So we re-draw the model with arrows pointing into life satisfaction. Again, we end up with a large negative coefficient for neuroticism (b = -.57, p < .001). Happiness goal orientation now has a positive coefficient (b = .16, p = .038) that may be considered significant, depending on your statistical creed. So here, assuming that neuroticism is causally prior to happiness goal orientation, one may conclude that not all of the association between happiness goal orientation and life satisfaction boils down to neuroticism.
Now we have two models which make different statements about (1) the structure of happiness goal orientation and about (2) the relationship between happiness goal orientations and life satisfaction:
- Bright/dark side: two types of happiness goal orientation, associations to life satisfaction could be mostly explained away by confounding with neuroticism
- Neuroticism all the way down: one type of happiness goal orientation but half of the items also happen to be affected by neuroticism, maybe there is a positive association with life satisfaction even after accounting for neuroticism. Admittedly, the latter claim hinges on weak statistical evidence, but p < .05 still counts for something in many articles.
So which model is the right one?
I can’t tell you. If you are really anal about model fit, you may prefer the two-factor bright/dark side model. But the difference in fit seems quite small, and in any case, if you’re that anal about model fit, you might not like either model because the Chi-Square test rejects both of them (see Fig. 6, Fig. 8).[8]Not that anybody cared about the Chi-Square test these days. If it keeps rejecting our models, it’s only fair that we reject it in return.
From the perspective of parsimony, we may prefer to add fewer “new” factors—if a single happiness goal orientation factor in combination with neuroticism can explain the data just as well, why add two? But then again, Krasko et al. (2021) started their observation from contradictory findings in the literature concerning the associations between happiness goal orientation and well-being. Splitting the construct in two factors, one of which is strongly infused with neuroticism (eau de despair), potentially clarifies the situation. But even if that’s the case for happiness goal orientation, what about other bright/dark side constructs? What are they good for?
Discussion: What to make of all of this
So we are in a situation in which we got a bunch of items that don’t really fit a one factor model. If we split it up in two factors, it can end up two ways:
- bright/dark side model with two correlated factors that both reflect the focal construct of interest (e.g., happiness goal orientations), one being correlated with good things, the other one being correlated with bad things
- two-factor model in which we have one factor for the construct of interest (e.g., happiness goal orientations) and a second one for whatever else affects some or all items (e.g., neuroticism).
It’s probably fair to say that the bright/dark side model is the sexy one. The other one would probably often be described as “contamination bias,” because we did not set out to measure neuroticism in the first place. This sets up a situation in which we can expect the bright/dark side model to dominate the psychological literature over its competitor. In the worst case, there will be natural selection for bad science here—assuming that the bright/dark side thing is bad science. But is it? Are those models wrong? What does wrong even mean in the context of factor analysis? Heck, should it even be called factor analysis, and not assumor analysis instead?
Carving nature at its joints
Let’s say we take a realist position and actually believe that some latent factors exist (in some sense of the word) and our research goal is to uncover them.[9]I think not many psychologists would claim they are factor realists when asked about it, but many articles nonetheless seem to imply some degree of realism. Which of the two competing models is the true one? Can we design a situation in which the two models make different predictions and then check which one fits better?
That’s where our original draft started to frazzle. I thought that maybe longitudinal or multi-rater studies could be helpful, but then I did some simulations and it seemed like that wasn’t really a way out (both models still made equivalent predictions in the scenarios I considered). Tailcalled brought up factor analysis applied to genomic data, and that does indeed seem to be a method used to discard certain factor-analytic models, although I’m not the best person to think this through for the bright/dark side problem.
E pluribus fewnum
One way forward that does seem promising are multi-construct studies. For a lot of the bright/dark side constructs, the “contaminating” factor seems to have the same flavor. For example, for those that are more “externalizing,” the distinction seems to be “I want something good for myself” (benign envy, narcissistic admiration) versus “I want something bad for others” (malicious envy, narcissistic rivalry), the latter maybe reflecting antagonism. For those that are more “internalizing”, the distinction seems to be “I try my best to get good things” (adaptive perfectionism, happiness strivings, acquisitive self-monitoring) versus “I try my best to avoid bad things because they are horrible” (maladaptive perfectionism, happiness concerns, protective self-monitoring). I hate to be that person, but maybe it was BIS/BAS—Behavioral Inhibition System, Behavioral Activation System—all along?
Let’s imagine you have N “substantive” constructs with a bright/dark side. You throw all items together, collect data, and run a factor analysis according to standard practices, including standard criteria for the number of extracted factors. I would be willing to bet that you would end up extracting N factors plus 1 or 2 (N substantive factors plus 1-2 bright/dark ingredients) rather than 2*N factors (N bright side and N dark side factors). In that case, it wouldn’t look very bright for the bright/dark side anymore.
Strictly speaking, the number of factors to extract is a matter of taste, even if it is based on (somewhat arbitrary) empirical criteria. There’s also nothing inherently empirical about extracting a small number of orthogonal factors. That mother nature shaves her orthogonally-jointed legs with Occam’s razor is just an assumption.[10]I guess there are valid reasons why psychologists (or Meehl at least) have been struggling with factor realism since the dawn of advanced statistics. But this still seems a promising way forward to break things down into something that could be labeled ingredients, and many people would be willing to take these as a more realistic description of what’s going on under the hood. At the very least, this approach would result in more parsimonious descriptive taxonomies.
Rose et al. (2023) have a paper reporting such a multi-construct study focusing on dark traits. They combine items from quite a few measures (Five Factor Model, Antagonistic Triad Measure, Dirty Dozen, BIS/BAS,…) and end up with four factors (which they label antagonism, emotional stability, impulsivity, and agency). Those results seem quite neat to me, but I may be a bit biased because two of them (antagonism, emotional stability) appear like the worst offenders when it comes to bright/dark side constructs.
Bainbridge et al. (2022) go even further. They included 42 personality scales and show that a large share of them could reasonably be considered as located within the Big Five, in the same manner that Big Five facets are located within the Big Five. Now that’s what I call an epic redemption arc for our five best frenemies! I can very much recommend taking a look at this study, at least check out the very cool figures locating the scales within the Big Five. This work is not primarily concerned with bright/dark side constructs, but it provides a good discussion of what should be expected from proponents of new scales. They should try to locate them within the existing taxonomy, and if the overlap with existing measures is very high, they should prove that their added scale has added benefits (in a much more rigorous manner than is currently done).
The multi-construct approach also seems a good way forward in scenarios in which the bright/dark factor appears to be mostly response bias which would be shared across pretty much all questionnaires. As a side note, I think the relationship between a response “bias” factor and a “substantive” contaminating factor isn’t straightforward:
- if you have a substantive bright/dark factor (say, antagonism), social desirability will probably “feed into it” because some people are more willing to report (or ascribe to others) antagonistic feelings and behaviors
- you may end up with separate factors for positively and negatively worded items, which screams “response bias.” But that response bias can still show correlations that appear to be substantively interesting (see e.g., positive and negative self-esteem)
- if your intended factor structure is a bit brittle, you can always mix in a healthy dose of response bias to support it. For example, grit supposedly consists of “consistency of interest” and “perseverance of effort.” In the Short Grit Scale, the items for the former are negatively phrased (“New ideas and projects sometimes distract me from previous ones”) and the items for the latter are positively phrased (“Setbacks don’t discourage me”).[11]Now that’s what I call a consistent effort to get mother nature to confess.
But like I said before, maybe carving nature at its joints is too lofty a goal to begin with. Maybe even a proper taxonomy is beyond grasp. How about something humbler?
Prediction 🔮
In psychological science, there’s “prediction”[12]This mode of inference allows you to say “X independently predicts Y beyond other factors” and then wink, which everybody understands to imply causality. If pressed why you’re not aiming for causal inference instead, you may say something like “a causal understanding is a very ambitious goal; prediction is a stepping stone towards it.” I think that type of approach usually sets you up to fail on both fronts, at least in psychology (where predictive accuracy is often humble). You’re not doing causal inference well because you pretend to do something else with different rules; you’re not doing prediction well because you don’t actually want to predict anything. and prediction. I believe that prediction may be a worthwhile endeavor if it’s done well and if there’s actually a point in predicting the outcome.
Studies establishing new constructs or questionnaires, including studies on bright/dark side constructs, will often allude to the fact that the constructs under consideration can predict some outcome (often, but not always, another self-report questionnaire). I think it would be great if those studies actually made an argument why we would want to predict the outcome to begin with. For example, well-being surely is important. But what do we gain if we find out that it is predicted by X? We can’t conclude that we should increase X to make people happier—for that claim, we need causal inference. We can use that information to predict who is unhappy, but then what? Most personality researchers are not in the business of rolling out targeted intervention programs. And even if they were, the “predicted” outcome in those studies usually occurs at the same time as the predictors. Being able to predict present well-being from a multi-item self-report questionnaire isn’t really that helpful; we could just hand out a multi-item well-being questionnaire instead.[13]There are exceptions, such as studies that look into the value of psychological constructs (often ability measures) for actually predicting occupational success. That literature is much more developed and tends to be more technically sophisticated than the average study trying to squeeze in one more self-report questionnaire. But I digress.
Let’s assume we really want to do prediction. What’s more useful, the bright/dark side model (e.g., chocolate obsession/chocolate appreciation) or the alternative model (e.g., chocolate liking + emotional stability)? If we’re thinking in terms of different rotations of the factor structure underlying the same items, it actually doesn’t matter at all—you get the same predictive bang for the buck. The coefficients will change but you’re not supposed to interpret them substantively anyway (recall you’re doing prediction, not explanation).
More interesting is the question whether the bright/dark side questionnaire is preferable over an alternative that takes the same amount of effort and time to collect. For example, if you can squeeze in eight items, what’s preferable for predictive purposes?
- four items to measure chocolate appreciation, four items to measure chocolate obsession
- four items to measure general chocolate liking, four items to measure emotional stability
- a single item to measure chocolate liking, seven items to measure emotional stability?
This is an empirical question and the answer will depend on
- the outcome to be predicted
- the actual questionnaires (maybe some of your measures happen to suck not because of the construct but because of the item phrasing) and
- other variables that are available for prediction
So the answer won’t be “bright/dark side construct yay” (or nay) but rather “for this specific predictive task, this particular questionnaire rather than that one, yay” (or nay). This answer won’t be very helpful if the predictive task exists only in the researchers’ imagination, never to be deployed in the real world.
I also suspect the bright/dark side constructs will not win very often when it comes to prediction. I have read quite a few studies in which the authors have to bend over backwards to demonstrate “incremental validity” (which is linked to psychology-style “prediction” rather than actual prediction). The number of additional predictors is usually kept low, measurement error is ignored, and even then, the added value is usually low and the statistical evidence often somewhat brittle.
But maybe when we say that constructs are useful for prediction, we mean something else—maybe we aren’t really thinking of quantitative predictions, but of something more casual. For example, we meet somebody who seems to have slightly narcissistic tendencies. Should we stay away? If they are mostly trying really hard to get others to admire them, maybe they’re fine or even fun to hang out with. If they are mostly trying really hard to put other people down, yikes.
Which leads us to a different research goal.
Helpful Description for Humans
The thing is, there are a lot of bright/dark side constructs out in the literature, and people dig them. That’s in itself an interesting observation!
Considering the high prevalence, the phenomenon probably has two sides:
- dark side: mixing up two constructs is a good way to craft one’s own niche in the literature. A lot of known findings can reliably be rediscovered (“Oh look! The dark side of X correlates with all correlates of neuroticism! Isn’t that interesting?”) and that also makes the questionnaire attractive for other researchers (citation machine go brrrrr).
- bright side: people keep generating bright/dark side structures because when they try to generate items to capture a certain construct, they are very likely to think of behaviors and thoughts that matter. What matters? Things that are functional or dysfunctional one way or another. Maybe antagonism creeps in because if somebody is antagonistic, that’s highly relevant information for future cooperation, so we’re very sensitive to that. Maybe neuroticism creeps in because we want to know whether we or other people are struggling, which may indicate a need for help. Another way to put this is that social perception may indeed have a bright/dark side structure, and maybe in the end all of our personality models are really just models of social perception.
These two aren’t mutually exclusive.
Beyond the pervasiveness of bright/dark side constructs, they also seem to have a broader appeal to humans in general (myself included, on my weaker days). In case you’re inclined to attend parties, any of these constructs will make for a more exciting small-talk topic than factor rotation methods. Why are they so attractive?
One contributing factor may be that they introduce some degree of nuance. Envy, pride, and narcissism appear like bad things. Pointing out that people who are highly envious may also channel their wickedness into positive behaviors (like trying to emulate the achievements of the target of their envy) demonstrates that it’s not all black and white.

Except that, of course, the bright/dark side constructs then go on and slice things into good and bad. But maybe because it’s contained within a broader construct, behavior change seems more plausible—keep the trait, change the manifestation. Instead of putting others down, couldn’t you just try to lift yourself up instead? Instead of being afraid of unhappiness, couldn’t you just strive for greater happiness? Of course, if you mentally rotate the factors that’s about the same as saying “don’t be such a jerk” or “don’t be so neurotic.” But the narrative is a different one, and maybe the narrative does facilitate change.
Whether that’s a good justification to pile yet another questionnaire onto the literature will very much depend on whether we consider crafting narratives that feel right and potentially helpful a central goal of personality psychology. If you ever went through the APA PsycTests database alphabetically, as Ruben did, you may conclude that it’s just not worth it; we just have too much stuff already. Are we really fine with doing superficially satisfying scholarly sanctioned self-help if it leaves our scientific literature in shambles?
Now if you excuse me, I’m going to revel in the consequences of the dark side of my scientific cynicism.
Footnotes
| ↑1 | Lastly, I will demonstrate that academic signposting (explicitly telling readers what comes next) is a bad writing habit that can only be justified if there is a mismatch between readers expectations and reality (“It’s more of an article than a blog post”). |
|---|---|
| ↑2 | Ruben maintains that this is not the case and that there should be a small positive correlation between the two. Allowing for such a correlation would not change the general pattern and our next example will include for a correlation between the two underlying factors, so all the Bridget Jones lovers out there can mentally insert r = .2 here. |
| ↑3 | This corresponds to a situation in which you use three orthogonal factors (your three fingers) to explain the space around you. Given that the space around you has three dimensions to begin with, your hand model is perfect. Hands! Wow. |
| ↑4 | That the unrotated solution corresponds to the truth is only because of the data-generating mechanism we simulated. If it always worked like that, this blog post would be a lot shorter. |
| ↑5 | We should do this with new data; we could do this with the data underlying the EFA (to cite Anne: “CFA confirms the factor structure you found in an EFA in the same dataset? d’uh”). Luckily, it won’t make a difference for the bright/dark side thing because it is not a matter of sampling variability. |
| ↑6 | Or just a tiny bit, for proponents of the Bridget Jones hypothesis. |
| ↑7 | If we wanted to fit that type of structure, the model would not be identified (unless we incorporated some additional constraints, such as the equality of certain loadings). |
| ↑8 | Not that anybody cared about the Chi-Square test these days. If it keeps rejecting our models, it’s only fair that we reject it in return. |
| ↑9 | I think not many psychologists would claim they are factor realists when asked about it, but many articles nonetheless seem to imply some degree of realism. |
| ↑10 | I guess there are valid reasons why psychologists (or Meehl at least) have been struggling with factor realism since the dawn of advanced statistics. |
| ↑11 | Now that’s what I call a consistent effort to get mother nature to confess. |
| ↑12 | This mode of inference allows you to say “X independently predicts Y beyond other factors” and then wink, which everybody understands to imply causality. If pressed why you’re not aiming for causal inference instead, you may say something like “a causal understanding is a very ambitious goal; prediction is a stepping stone towards it.” I think that type of approach usually sets you up to fail on both fronts, at least in psychology (where predictive accuracy is often humble). You’re not doing causal inference well because you pretend to do something else with different rules; you’re not doing prediction well because you don’t actually want to predict anything. |
| ↑13 | There are exceptions, such as studies that look into the value of psychological constructs (often ability measures) for actually predicting occupational success. That literature is much more developed and tends to be more technically sophisticated than the average study trying to squeeze in one more self-report questionnaire. |
What a great read. Thank you for writing this, I learned a lot from it!
Regarding the discussion of the findings I want to add another perspective and would be curios what you think of it. Namely, that many of the items for neuroticism, life satisfaction and happiness concern refer to very similar phenomena. Someone who says “I worry a lot” cannot really agree to a statement saying “My life is close to my ideal” without contradicting themself. However, this is not the result of a psychological effect, but rather stems from the meaning of the words “worry” and “ideal life”.
In the same way, when you say that someone is a neurotic person, what u are saying is that this person is anxious, often scared etc. If your statement is true, this person should be more likely to be concerned about their happyness. But again, not because one causes the other, but because this is what follows from the description of being often anxious. Looking at it from this angle, it doesn’t really make sense to describe one thing as causally prior to the other. Neuroticism is a term we use to describe that some persons tend to be anxious across a variety of situation. Thinking about your life is one of these situations. I would also argue that you can’t really falsify relationships between the three constructs without changing what these constructs mean (or better: questioning whether you really measured them). I would suspect that looking at the items (and meanings) of dark side/bright side constructs one can often find such semantic relationships between constructs.
Btw I would still see contribution in the paper by Krasko et al (2021). Namely that when we talk about striving for happiness goal orientation, we can mean two different things: One where you worry a lot about whether u will be happy in the future. And the other where you actively invest efforts to be happy. While it’s not clear whether the second one helps to find satisfaction (and therefore warrants an empirical examination), the first one is not really compatible with being fully satisfied with your life.
Anyways, this has already gotten pretty really long and I’m myself not sure what to conclude out of it 🙂 But I hope it adds another perspective and I’d be really interested to hear what ur thoughts on this are.
Cheers
Lars
Hi Lars,
Thank you for the insightful comment!
Those are interesting points that (I think) directly relate to the question of how we conceptualize personality traits. Is anxiety essentially a summary of “anxious in many situations, about many things” (so that anxiety about happiness -> anxiety); or is anxiety an underlying latent trait that can manifest in many different ways (so that anxiety -> anxiety about happiness).
The semantic overlap also raises many questions to me — is it overlap on the item level (i.e., maybe you simply picked the wrong items?) or on the construct level (this may be what you mean when you say it’s impossible to falsify relationships between the constructs)? And where does it “come from”? Does it render the associations tautological (maybe it has to be that way, a priori) or is it just that language also captures associations that we (collectively, as humans) have acquired? For that, maybe it is interesting to consider whether we can conceive a world in which the associations weren’t there. Taking happiness and neuroticism as an example: what would it look like if these two weren’t associated, or maybe even associated positively? Personally, I could imagine a scenario in which the happiest people were also most worried (because they have more to lose); but one could also argue that this results in a different concept of happiness.
Anyway! As you might have noticed, I haven’t thought this through. I think it’s an important topic because it affects whether/how we can speak of personality as a cause of anything. I also suspect it’s closely related to the notion of fat-handedness that Eronen & Bringmann discuss here: https://journals.sagepub.com/doi/10.1177/1745691620970586. I also suspect that there may be an answer out there in the more philosophical literature on personality, which I often find very hard to read (and sometimes conceptually confused in its own right).
This has gotten pretty long as well 😉 I also definitely see a contribution in the paper by Krasko et al., it’s really not wrong in any technical sense, and definitely adds some degree of clarity to this particular literature.
Best
Julia
Thank you for your response Julia!
I like the idea of trying to conceive a world where such associations do not exist or are reversed. And I think we should start to be very sceptical, if we conclude that this would change the meaning of one of the concepts itself. It really shows that they are intertwined in some way.
I also think that it is preferable to only assume an underlying latent trait (or any other theoretical construct), if we actually need it to explain a certain phenomenon that we observe in the world. We ended up with the personality constructs that we have by observing a lot of people and seeing that there are stable differences in how emotionally stable, conscientious, etc. they behave across various situations. I think we can simply take it that way. Assuming an underlying latent trait doesn’t improve our understanding of this phenomenon (it rather mystifies it, i think?). It might well be necessary to explain other phenomena, which I don’t know about since I’m no expert on personality, but if we assume a construct of neuroticism only to explain that people are emotionally unstable across various situations, it seems of no explanational value. We can still say something about how, for example, conscientiousness predicts future job success, but then it’s not conscientiousness as a thing that leads to success, but when people constantly invest a lot of effort in their work.
This might seem nit-picky but my guess is that some of the conceptual confusion/chaos stems from reifying psychological constructs and thinking of them as something that actually exists and acts in the world. I would say we have no reason to believe that neuroticism or happiness concern exist as real “things”. They are terms that describe certain behaviors and experiences that we can reliably observe at humans. I also wouldn’t see the associations between the constructs as necessarily tautological, but rather as describing similar phenomena, maybe at different levels (more specific vs. more global).
Well, I hope this didn’t itself become too confusing 🙂 If it doesn’t make sense for you, I’m happy to hear about that, I’ll definitely have to think about this some more..
Thank you already for this discussion, it really helped me to think through some things!
Best
Lars