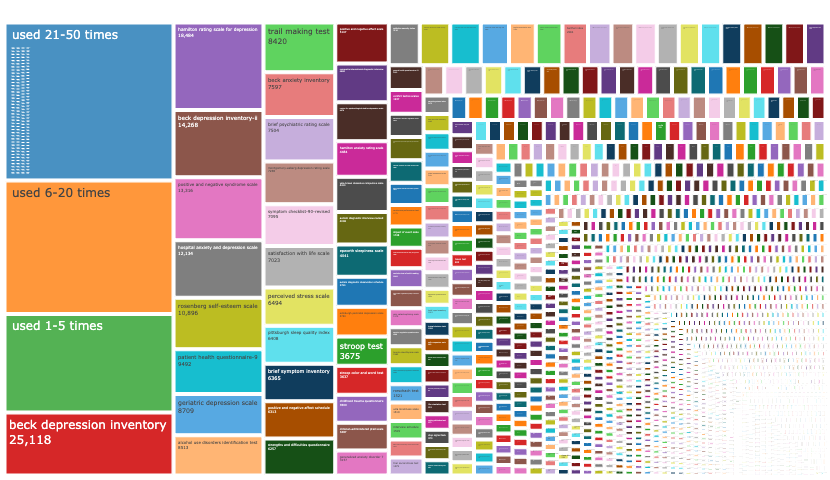
Recently, Malte, Taym, Ian and I wrote a short commentary paper on the toothbrush problem for measures in psychology: Everybody has one, and no one likes using anyone else’s. In this paper, we visualise data collected by the APA to show that many psychological measures are never or rarely reused by others and that the number of measures in existence is growing massively and excessively, which we term proliferation. We argue this threat to cumulative science could be resolved if we raised the bar on creating and modifying measures and took care to avoid redundancy.
The piece was short and opinionated and we reported only a few graphs [1]one of which I had to correct. Together with Farid Anvari in the lead and Lorenz Oehler, we followed up on this piece with a preprint, in which we take a more in-depth look at measure and construct proliferation in psychological science. In it, we break things up by subdiscipline and reflect on what exactly these patterns can tell us.
Just as we were wrapping up the preprint, Communications Psychology published an opinion piece by Iliescu et al. (2024) that is sort of but not really a reply to our Toothbrushes paper. The authors argue, as they write in their title, that “Proliferation of measures contributes to advancing psychological science”.
Now, to be honest, we were very tempted to turn this into an epic[2]academic battle[3]armchair back-and-forth that’s less about being right and more about who gets the last word. We may even have created an AI-written, AI-vocalised rap battle. However, on closer inspection, the steam kind of dissipated. We now suspect we agree more than the exchange (or a rap battle) would lead a cursory reader to think. We decided to write this blog anyway because if there is one thing that advances psychological science, it’s the proliferation of comments and replies. So, some quick clarifications are in order. We hope that the preprint also helps to clarify how we view the problem. In it, we had more room for the nuance that the brief commentary may not have had.
As is so often the case in psychology, some of the disagreement may be coming from an unclear definition of the concepts involved. Some of the authors’ responses can be read as if they understood us as saying that the creation of new measures should be curtailed. For example, they say that “We suggest that proliferation of measures is not per se a negative phenomenon, but strongly depends on how it is situated and that it can be bound into the very fabric of how psychological science develops.”
We do not disagree that growth in the number of available measures can be good. However, by proliferation we mean excessive, unchecked growth. We especially find the “unchecked” part problematic — many measures are not pretested, subjected to stringent construct validation, checked for redundancy, or in fact ever used again outside of the primary study for which they were developed and used. We created the SOBER guidelines precisely because we want checked growth, not because we want measurement development to cease.
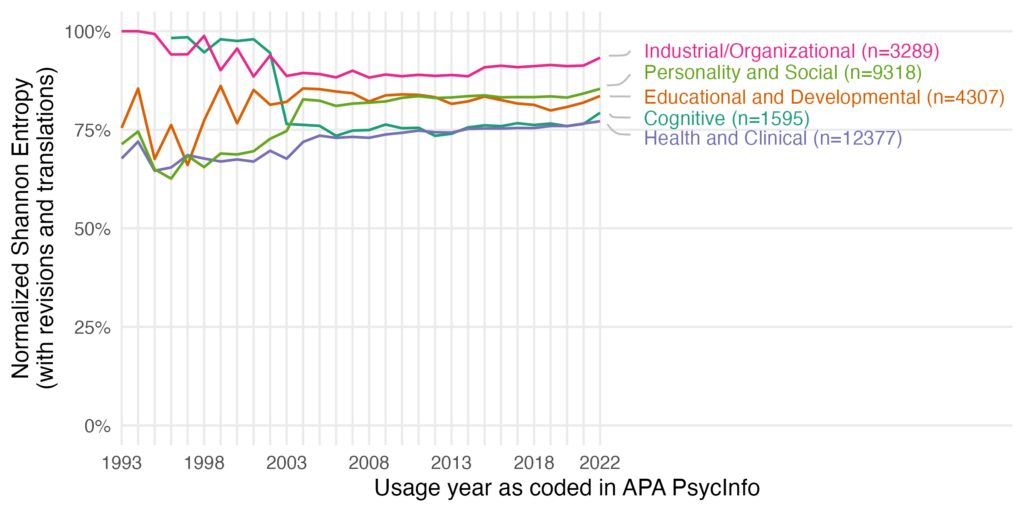
The key problem we’d therefore like to solve is fragmentation, which we operationalize using normalized Shannon entropy (“closer to 0%, a few measures dominate; closer to 100%, measures are used an equal number of times across publications”). We argue that as long as measures are created and discarded rapidly without integrating them into a broader body of work through construct validation etc., we will see fragmentation. We are absolutely fine with new measures being created, if they meet the quality standards (e.g., our SOBER guidelines).
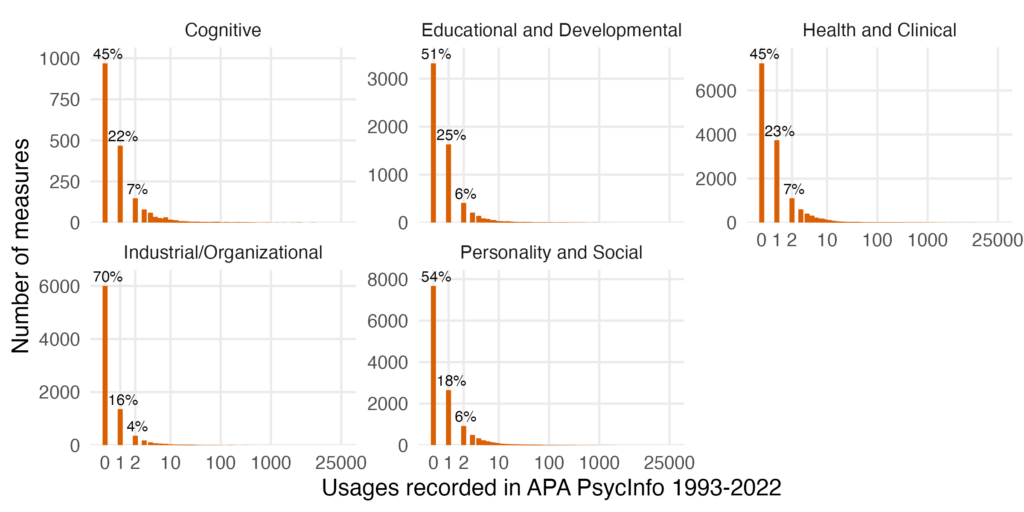
We suspect one of the key things causing disagreement is the area of focus. Some of the authors are or were editors of measurement-focused journals. They see researchers who invest their time to push the envelope and improve measurement in psychology at the cutting edge, authors who are on top of how best practices evolve in their field. But a lot of measures are developed outside of assessment-focused journals, with comparatively little effort, in the course of primary research. Few of them may be memorable, but collectively they are many. One of the key points illustrated by the data in our Toothbrushes paper, the new preprint and of course Flake & Fried’s schmeasurement work is that developing bespoke measures as a sort of afterthought in primary research appears to be common: most measures are used just once or only a few times and researchers are often not transparent about their procedure and adjustments.
We think operationalising and quantifying fragmentation is very helpful because, clearly, informed readers can disagree. For example, Iliescu et al. write
“In fact, one could argue that there are few (if any) psychological constructs that exhibit as much measurement proliferation as [general mental ability (GMA)] showing that sometimes theory and validity development go hand in hand with the proliferation of measures.”
Iliescu et al. 2024
This was surprising to us. We agree that the GMA/intelligence literature is a good literature to emulate with respect to measurement. Research validating novel measures against existing measures is common, finds convergence (latent correlations approach 1), and the effort going into measure development is high. Most people do not create an intelligence test ad hoc, in fact we doubt there exist tests of general mental ability that have been used only once or twice. We agree this is a comparatively good field.
But we think things are worse for many or most other constructs and measures. According to our operationalisation of fragmentation, it is not true that there are “few (if any) psychological constructs that exhibit as much measurement proliferation”. We have data to support our position. In APA PsycTests, tests are classified in broad rubrics. With a normalised entropy of .51 for aptitude and achievement and a .53 entropy for intelligence, these two classifications are in the bottom five for entropy out of 31 classifications. So, other classifications, like Personality with .69 or Organizational, Occupational, and Career Development with .79 clearly have higher normalised entropy. Now, maybe the authors think our operationalisation of fragmentation is incorrect, or they consider the comparison unfair in other ways. But with a precise operationalisation and quantification, we can discuss this and maybe come to an agreement.
We don’t rely exclusively on the measure of fragmentation to make the case that proliferation occurs. We also point to the fact that there are thousands of measures and constructs published every single year and that the absolute majority of these are used only a very few times. And the thousands of measures and constructs that are recorded by the APA in their databases are only a part of the full number of constructs and measures that are published, since the APA’s recording standards involve recording only measures that are not “marginal”. APA’s recording also does not take into account the sort of flexibility in measurement that focused reviews of the literature often unearth.
While we agree with the authors of the commentary on some cases of desirable growth, we also see evidence for unchecked, excessive growth: i.e., proliferation. Some of the authors of the reply seem to agree with this.
So, maybe there is more agreement about the state of specific fields, but we differ in what measures we are commonly exposed to and hence what we focused on in our recommendations and comparisons. Some of the authors of the reply work in cognitive or clinical psychology. According to our new preprint, these subdisciplines are comparatively less fragmented than personality and social psychology or than I/O psychology, our respective backgrounds. A good way to see this is to look at the treemap plots. I/O looks a lot more fragmented than clinical (see all treemaps here, but give it some time to load).
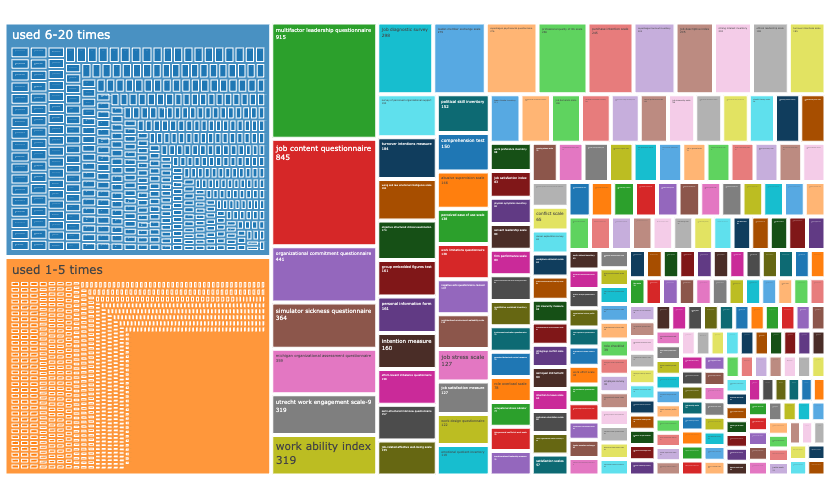
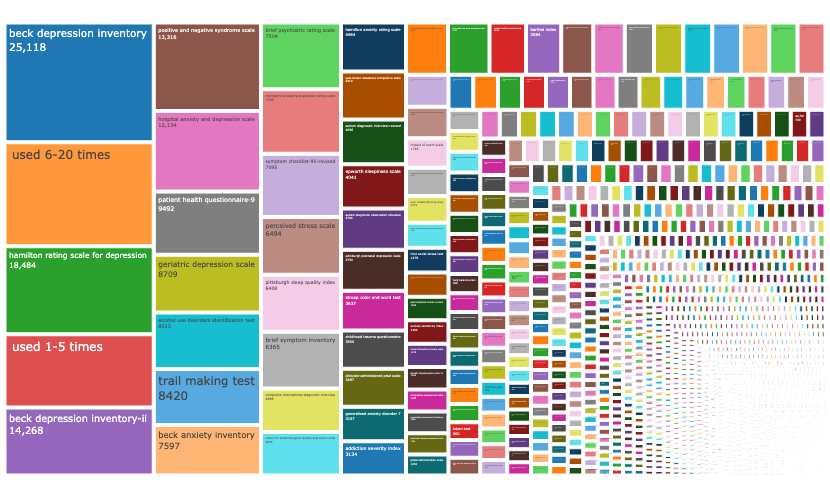
In summary, we do not want to prevent the development of new measures. We do indeed want to raise the bar for releasing new measures into the wild and for modifying existing measures. However, our hope is that a higher bar will lead teams to pool their efforts, so that we get a few good measures and well-validated revisions and translations rather than hundreds of poorly validated measures that are hardly comparable.
Our vision is one of open, living standards that evolve over time at internet speed, like HTML, not one of copyrighted, crusty standards that cannot evolve until all the subcommittees and sub-subcommittees have found a way to meet, like the DSM. We are very interested in discussing how to best achieve this vision, what role bottom-up and top-down processes have to play, how to avoid the failure mode of proliferating standards, and in hearing about the experiences of those involved in related efforts like HiTOP.
Footnotes
| ↑1 | one of which I had to correct |
|---|---|
| ↑2 | academic |
| ↑3 | armchair back-and-forth that’s less about being right and more about who gets the last word |