
I don’t like getting into fights and sometimes I am concerned this keeps me from becoming a proper methods/stats person.…
I don’t like getting into fights and sometimes I am concerned this keeps me from becoming a proper methods/stats person.…
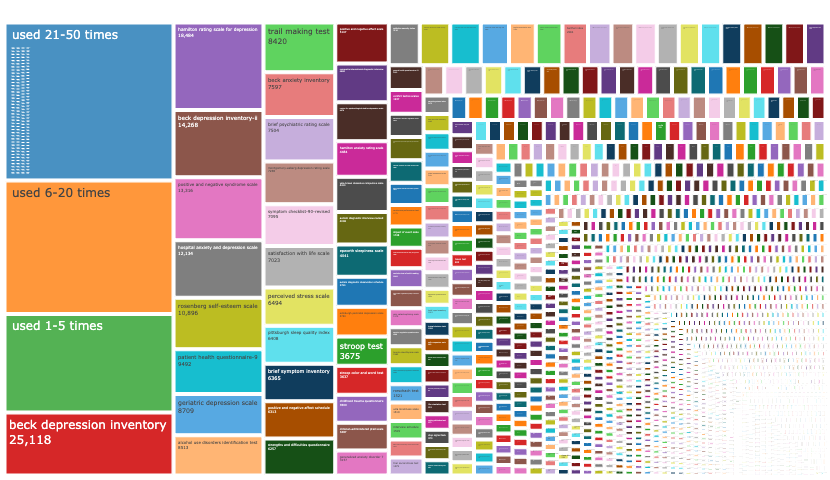
Recently, Malte, Taym, Ian and I wrote a short commentary paper on the toothbrush problem for measures in psychology: Everybody…
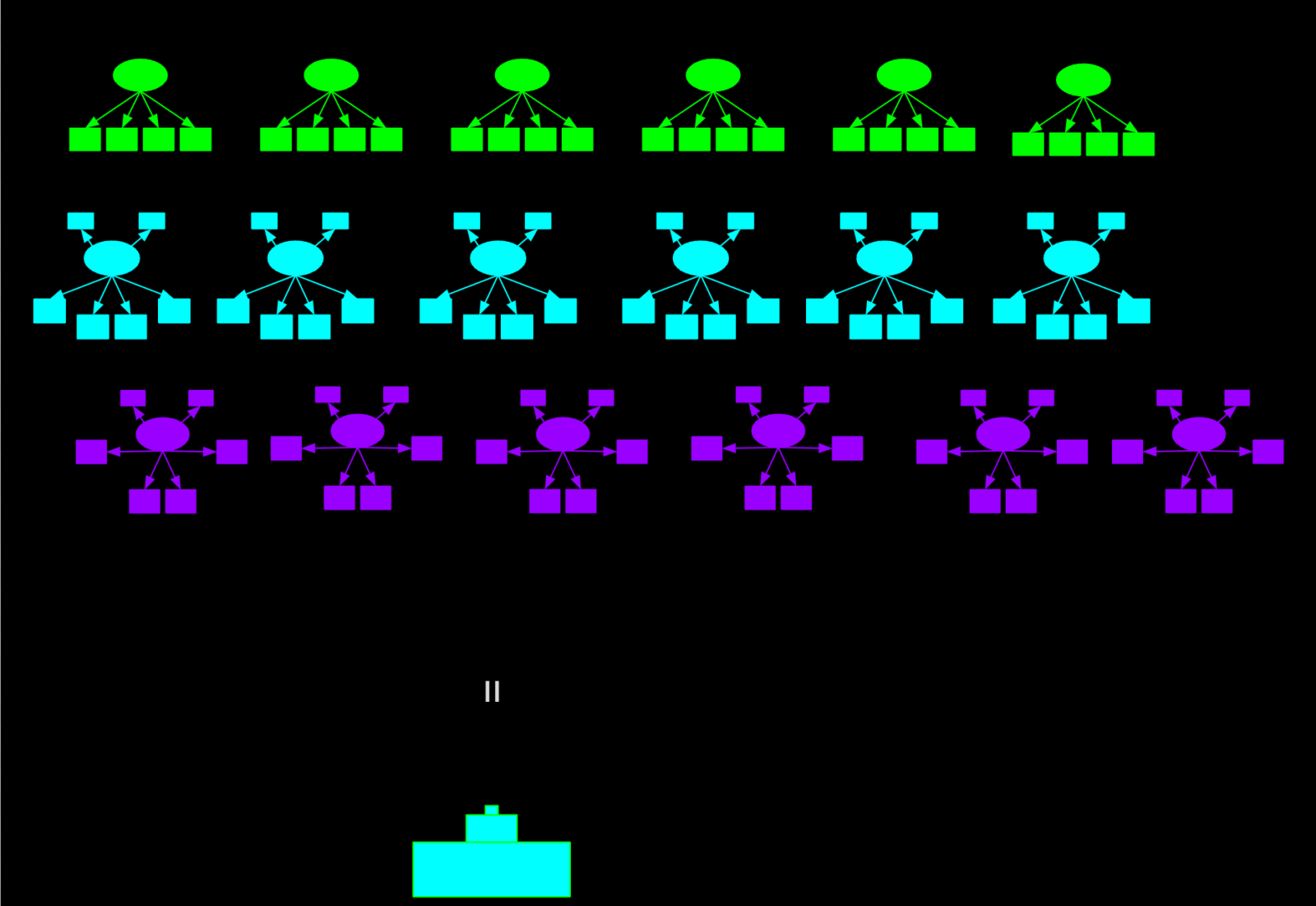
Testing for measurement invariance is one of those things where researchers roughly fall into two categories. Either they consider it…
This blog post resulted from a draft that was supposed to become a proper article at some point. Michael Dufner…

Earlier this year I saw that a study was making the rounds on Twitter under the catchphrase “Representative samples may…

Content warning: half-assed philosophy of science Part I: Causal Inference I am not very keen to join the stats wars,…
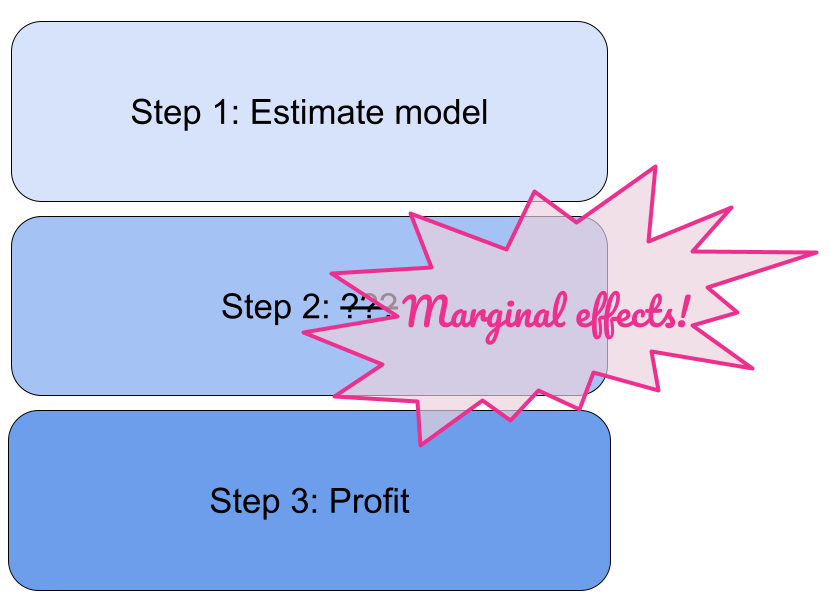
Let’s admit right away that “marginal effects” doesn’t sound like the most sexy topic. I’m not saying that to further…

After a decade of “replication crisis”, “reproducibility”, and “open science”, it’s time for a deep dive into the rabbit hole.…

It is the curse of transparency that the more you disclose about your research process, the more there is to…

Estimated reading time: 8-10 minutes To get the boring stuff out of the way: Of course I’m not against scientists…