Let’s admit right away that “marginal effects” doesn’t sound like the most sexy topic. I’m not saying that to further marginalize these poor effects. It’s just that statistics, in and of itself, barely gets anyone’s juices flowing, no matter how hard you try to make your plots look like genitalia.[1]Can’t unsee Abbildung 2.
But marginal effects are one of those really valuable pieces of the puzzle that make other seemingly unconnected things fall into place. All those convoluted coding systems for categorical variables. Why people habitually center predictor variables before calculating their product term to investigate interactions. Why everything “interacts mechanically” in a logistic regression, and, quite generally, why you might have done interactions in nonlinear models the wrong way (although that sort of depends on what question you were trying to ask in the first place). I learned about the whole idea of marginal effects relatively late, and that made all those things more puzzling than necessary. If somebody would have told me earlier, that would have been great.
But Vincent Arel-Bundock just dropped a big release of the R package marginaleffects (check out the really detailed documentation here) which allows you to calculate marginal effects for more than 60 classes of models in R, and Andrew Heiss[2]Who was so kind to comment on an earlier version of this blog post, for which I am very grateful. Of course, he bears no responsibility for any mistakes I made, let alone for any inappropriate joke. wrote a super helpful comprehensive (“75-minute read”) blog post on marginalia.[3]Thus scooping the best English pun we could have come up with. Aber ich marg ihn trotzdem. Still, they left a margin for me to write my own blog post – so let’s talk marginal effects. This piece will be as non-technical as possible (pinky promise). If you want to go into more depth, definitely check out Andrew’s blog post (which is still very accessible) and the marginaleffects documentation. You could even go and check out the chapter on it in the Stata manual (although there is a good chance that if you’re using Stata, you’re working in a field where marginal effects are more well-known and thus don’t need this blog post).
Stats 101, in a nutshell
This is oversimplifying things a bit, but think of statistics as a two-step process (Figure 1, Panel a).
Figure 1
Add a Figure, they said. It will add value, they said.
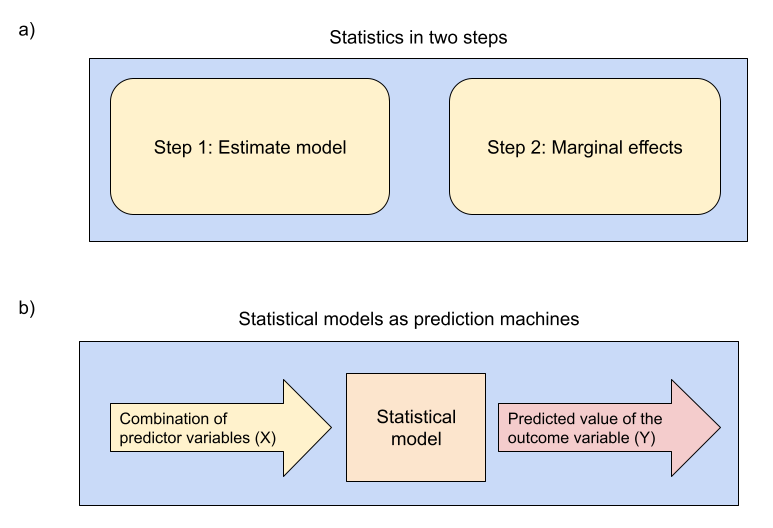
In the first step, you build and estimate a statistical model. In the second step, marginal effects.
Think of the model as a prediction machine (Figure 1, Panel b): you can plug in any combination of predictor variables and it will return the predicted outcome value for that particular combination. This model could essentially be anything, from a simple t-test to psychologists’ favorite, the ANOVA, to regression with all its beautiful variations (hierarchical/multilevel/mixed models, all non-linear variations such as logistic regression…). You then use this model to generate all sorts of predictions, contrast them for different scenarios (e.g.: [Y: Your predicted knowledge of marginal effects for X: You continue to read this blog post] minus [Y: Your predicted knowledge of marginal effects for X: You stop right now and go do something else]), and aggregate them if necessary to answer your questions. Those are your marginal effects.
Will this process provide the right answer? It depends, obviously. Your data may not be able to provide good answers, maybe it’s biased or just not enough. Your model may not appropriately capture the data and cause issues. The coefficients of interests may not be causally identified, so that the resulting marginal effects really aren’t effects in the narrower sense at all, but some spurious mess (we will still call them effects for the purpose of this blog post). These are all issues in which you can read up in some detail in the psych literature. But, importantly, even if all these issues are taken care of (big if), you still have to query your statistical model in a way that it returns an answer to the question you are interested in. In many cases, you need to calculate a marginal effect. That step–asking your model a precise question–seems sometimes a bit neglected in psych, to the point that we turned it into the title for our interactions paper, “Precise Answers to Vague Questions”. But it’s also something that’s simply neglected during our training, so one might be forgiven for thinking that a regression analysis ends with regression coefficients, when they are often just an intermediate result.
Figure 2
Me: *not exactly sure what question I am trying to answer*
Statistical model: *returns a precise result down to the third decimal*
Me:

Example 1: Constant motion 🛤️
Let’s start with a very simple example. There is a runaway trolley barreling down the railway tracks at 10 meters per second (36 kilometers per hour, or 22.3694 miles per hour), on an even plane. For simplicity, let’s assume that no forces (such as air resistance, friction, people tied up on the tracks) are involved, so that the trolley just keeps moving at constant speed, away from you in a straight line. To predict Y (the distance between you and the trolley, in meters) from X (time elapsed since the trolley left where you are standing, in seconds), we can use the following equation: y(x) = 10*x. To “use” such an equation, you simply take a value of X that is of interest to you and plug it in and type it into your calculator. Here, you probably won’t even need a calculator, but once equations get more complex you probably will. If you want to make your middle school physics teacher a happy person, add units (x is measured in seconds, y is measured in meters, so the coefficient would be 10 meters per second). Figure 3 visualizes this model.
Figure 3
The World’s Easiest Trolley Problem.
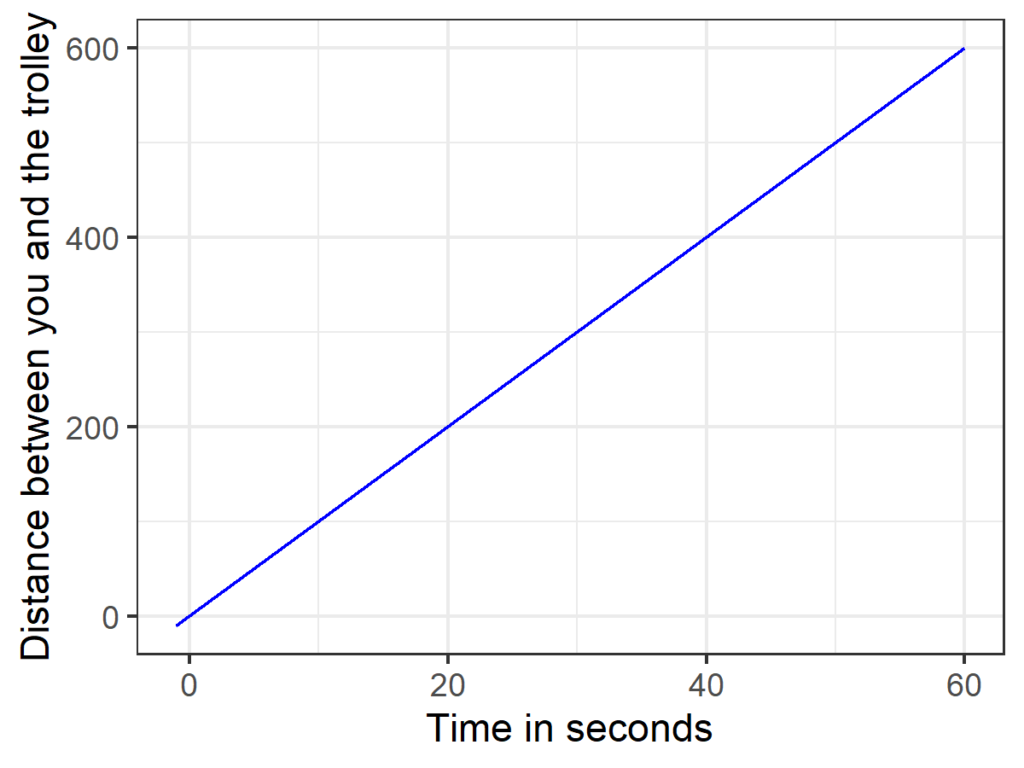
Now we are done with Step 1, we have got our model. We only have one predictor and the model isn’t exactly complex, so there’s pretty much only one marginal effect that we can calculate: The effect of X (time elapsed) on Y (distance between you and the trolley). The answer is as trivial as it gets: it’s 10 meters per second, the speed with which the trolley is traveling. There are different ways to get that number. We could use Figure 3 and draw a slope triangle. We could plug in two values for X and take the difference: after 10 seconds, the trolley is at 10*10 = 100 meters, one second later it is at 10*11 = 110 meters, so it traveled 110 – 100 = 10 meters per second. We could calculate the first derivative (it’s a constant, 10). And we can directly get that number from the model coefficient in front of the predictor. It says 10 right there!
This may feel a bit trivial because frankly the model is trivial and I already told you the speed of the trolley. But if the only statistical model you are ever using is univariate linear regression–one predictor, draw a single straight line, no frills–that is pretty much all there is about marginal effects. It’s the slope of the regression line, which you can read off the single regression coefficient.
Unfortunately, when things get more complex, this equivalence–regression coefficient of a predictor == its marginal effect–often breaks down. In those situations, the regression coefficients still tells you how to calculate the outcome variable Y for any combination of predictor variables. But we can no longer take for granted that the coefficient of a predictor reflects the effect of the predictor on the outcome in a straightforward manner.
“Things getting more complex” involves all scenarios in which the effect of a variable may vary–for example, when the effect of a variable depends on another variable (aka interaction, or effect modification). Here, the question “what’s the effect of X on Y” is suddenly underspecified to begin with, because according to the model, the answer depends on the value of a third variable.
“Things getting more complex” also involves anything outside of the realm of linear regression, such as logistic or probit regression. The logic of both types of regression is very similar to linear regression, except that our (linear) regression equation does not model the actual outcome of interest (which can take on the values 0 and 1) directly, but instead a nonlinear transformation of it. Because of that transformation, “the effect of X on Y” again varies. For example, if X is a continuous variable, a 1-point-increment from 0 to 1 may have a different effect than a 1-point-increment from 1 to 2. In that sense, in such a nonlinear regression, every variable “interacts with itself.” And if multiple predictors are involved, the effect of any of them will automatically depend on all others, even if no interaction terms are included–a phenomenon that Simonsohn has labeled “mechanical interaction.”
But, to stay with the trolley, let’s look at the easiest possible more complex example.
Example 2: Oh no, the trolley is accelerating!
Let’s imagine the trolley was speeding away from you on an inclined plane. Apart from that, there are again no additional forces involved.[4]So don’t worry whether the trolley is accelerating toward anyone–in the vacuum of our thought experiment, nobody can hear them scream anyway. The trolley will now accelerate constantly, which means that its speed is changing, but at a constant rate. Let’s say we can now predict the position of the trolley with the following formula: y(x) = 0.25*x², see Figure 4.
Figure 4
Accelerating trolley. Homework assignment: After how many seconds has it reached the speed of light?
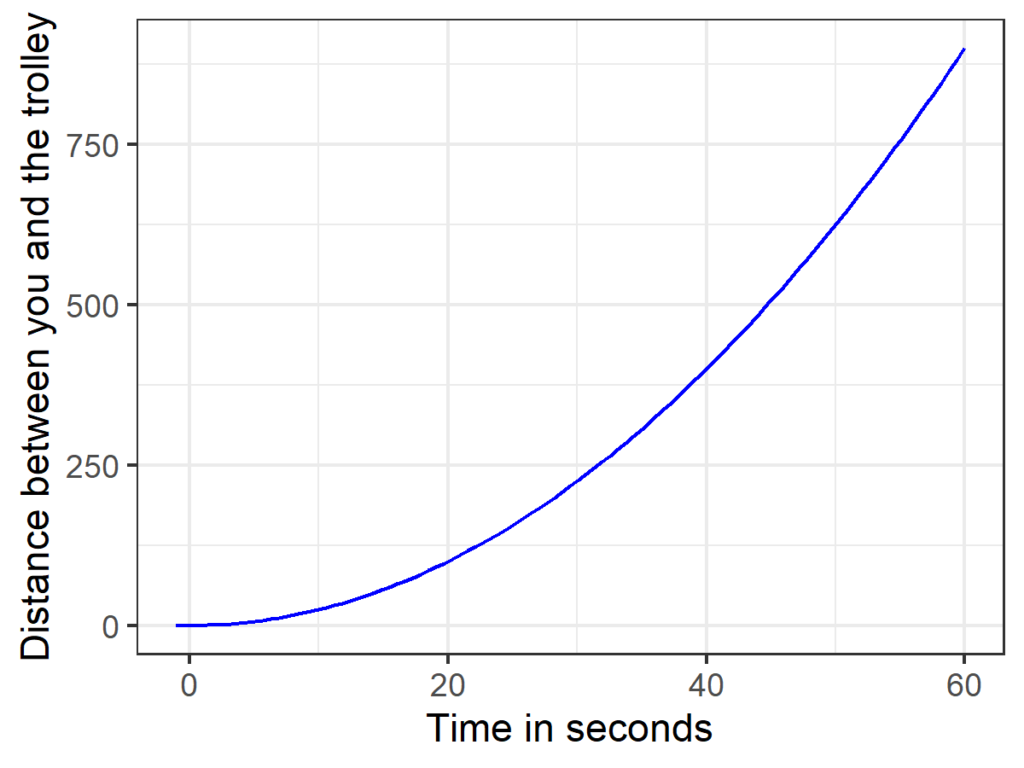
What’s the effect of X (time elapsed) on Y (distance between you and the trolley)? In other words, how fast is the trolley traveling? Duh, it depends. It starts at 0 meters per second and after one minute, it’s like, much faster. Thus, we already know that the coefficient 0.25 from the equation describing the position of the trolley can’t possibly be the answer. But we can still calculate the precise speed at any point in time. Again, there is a graphical solution for this (take Figure 4, draw a tangent line and calculate its slope). We could also still plug in different values for X and take the difference of the predicted Ys, except that if we want to predict the speed at a single point in time, the difference between the X values we plug in has to be like really really small, as in infinitesimally small. If you figure out how to do that, congratulations–you reinvented differential calculus. If you learned differential calculus in high school, things get a bit easier because you already know that you need to determine the first derivative of the equation above, and that there are straightforward rules to do so (and even online calculators to do the job). Here, the equation that gives us the speed of the trolley at any point in time is 0.5*x. In other words the trolley gains 0.5 meters per second per second, see Figure 5.
Figure 5
First derivative of Figure 4. See derivatives of polynomials, although one could also apply the inverse of Tai’s method for the determination of total area under a curve.
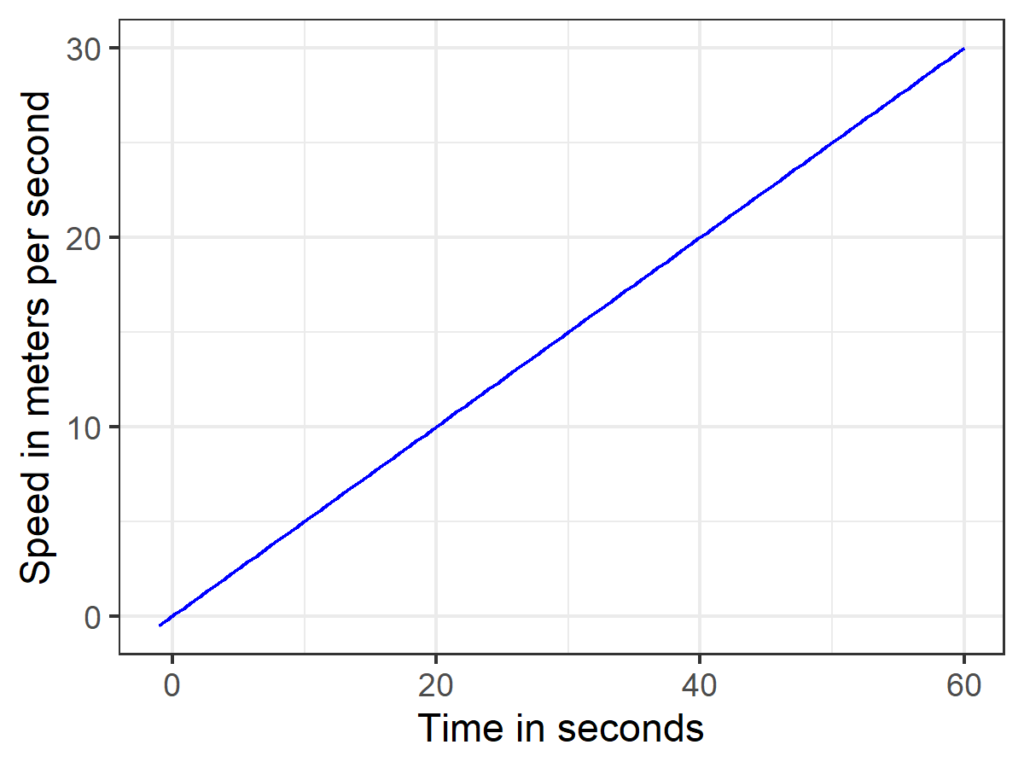
Now, we can still answer all sorts of questions about the speed of the trolley at any point in time, or questions like “the average speed of the trolley in the first 60 seconds.” And how about “a new trolley is put on the incline every 20 seconds, what is the average speed of all trolleys on the track after 5 minutes”? That might sound like your physics teacher went nuts, but it’s also getting closer to the type of marginal effects we are going to calculate next. For all of these questions, you can no longer directly read the answers off the initial equation describing the position of the trolley, you have to do some manual math first. That is something you’d usually want to avoid if models get more complex, so now let’s move on from simple equations of motion to an actual statistical model in the wild.
As a side note, we are now going to switch from a continuous predictor (time in seconds) to a categorical predictor. This makes it easier to think things through, because we do not concern ourselves with derivatives. In his blog post, Andrew Heiss says that only in the continuous case—where we have to consider derivatives, i.e., the instantaneous slope, i.e., the change in the outcome associated with an infinitesimally small change in the predictor—it’s a marginal effect; for categorical predictors–where we consider the change associated with a discrete change in the predictor—it’s just a “conditional effect” or “group contrast.” The Stata manual, in contrast, does not make that distinction but notes that some people use “partial effect” to refer to the categorical case. You may adopt whatever terminology you like (just use what the cool kids in your field use). The terminology is distinct from the general idea underlying those effects (Figure 6), and I really just care that you get the general idea: we look at what our model predicts happens with the outcome if we change a predictor one way or another.
Figure 6
A finger pointing at the moon is not the moon. Unless you really enjoy getting into arguments on Twitter.

Example 3: Do deskmates become friends?
Tamás Keller and Felix Elwert, two sociologists with whom I have collaborated, planned and conducted a large field experiment in which the seating chart of 182 school classrooms was randomized to investigate whether kids who sit next to each other are more likely to report that they are friends at the end of the school term.
I did the analyses, and they got a bit more complicated because (1) the outcome (mutual friendship) is dichotomous, so we need a non-linear model, (2) students are nested within classrooms, and (3) the unit of analysis is any pair of students within a classroom, so each observation is also nested within students. Now you don’t need to follow the technical details of this model to follow the rest of this blog post, but just in case you’re interested: We accounted for these things by (1) using a probit model (which models a latent continuous friendship propensity, and if that takes on a positive value, we predict the dyad will be friends), by (2) including classroom fixed effects[5]If probit + fixed effects makes you wince (are you an economist by any chance?) we also did a variation that replaces classroom fixed effects with the size of the classroom. And a linear probability model, because we tried to make readers from all fields of the social sciences happy. (so every class may have their own unique baseline friendship propensity), and by (3) including student random effects (every dyad is nested in two students, so technically it’s a multi-membership model).
You can look up the details in the published article, but what matters here is: we got all sorts of things in the model, but it’s still just a prediction machine—one that tries to tell if two people will be friends. Wouldn’t that be helpful in real life? Substantively, we are interested in what happens to friendship when a dichotomous variable, “deskmate” switches from 0 (the two students are not seated next to each other) to 1 (the two students are seated next to each other). The probit regression coefficient of that dichotomous deskmate variable is 0.27. So, the effect of being seated next to each on friendship is 42 0.27. 0.27 of what, you wonder? Well, 0.27 of “latent continuous friendship propensity”, whatever that is. Now this coefficient is different from zero, which may render it publishable depending on the field–but to actually understand what we can learn from the model, we need to figure out what it predicts with respect to actual friendships.
In principle, we can manually compute what our estimated model says for every pair of students in the data. For this, we plug the corresponding values (their classroom fixed effect, their student random effects, the overall intercept) into the regression equation and set “deskmate” to 1. We thus calculate the predicted latent friendship propensity for a pair of students, which in a last step we translate into an actual prediction of the outcome (friendship, yes or no) by checking whether it exceeds the threshold implied by the link function. Now we know what the model predicts in case those students are seated next to each other.
Next, we repeat the same exercise but set “deskmate” to zero. Now we know what the model predicts in case those students are not seated next to each other.
Last but not least, to get the effect of sitting next to each other on friendship for this particular pair of students, we take the difference between the two predictions. Here, we get one of three possible outcomes. The students are only predicted to be friends when they are seated next to each other (1 – 0 = 1), sitting next to each other doesn’t make a difference (1 – 1 = 0, 0 – 0 = 0), and, at least hypothetically, actually sitting next to each other turns them into non-friends (0 – 1 = -1).
In the end, we have an estimate of the causal effect for one particular observation in the data. This estimate may look different for other pairs of student in the data, because this is a non-linear model–whether the deskmate variable “pushes” a particular pair of students over the threshold for a friendship or not will depend on, for example, whether those students are more or less likely to befriend others in general (i.e., on their random effects). So we’d have to repeat the math for all 24,962 pairs of students in the data who could have become friends. Except doing this manually would of course be horribly tedious, even more so if we can’t afford student research assistants.
AME, the mother of all marginal effects
But this is the 21st century and I already told you that your statistical model is nothing but a prediction machine. For example, in R, after estimating pretty much any model you can come up with, you can use predict() or some alternative function to generate predictions for old and new data within seconds. So we can copy our data, set “deskmate” to 1 for every observation, and generate predictions. Here, we could do a short break and summarize our predictions to answer the question “What does the model predict if every pair was deskmates?”; such a summary of predictions is called a margin (according to the Stata manual). But let’s move on and copy the data once again and set “deskmate” to 0 for every observation and subtract the results.
We end up with estimates of the causal effects for every single observation. One very natural way to summarize the distribution of these causal effects is simply taking the arithmetic mean. In our deskmate paper, this mean turned out to be 0.07, which means that being seated next to each other increased students’ friendship probability by 7 percentage points on average (from 15% to 22%, those are the two margins involved in this prediction). This is the so-called average marginal effect (AME), the mother of all marginal effects.
A technical detail that is important in practice: So far, we have completely ignored any uncertainty in that estimate, and usually we want more than just a point estimate. In our deskmate paper, we used a Bayesian approach, and that allowed us to draw from the posterior, which is a very neat generalized way to quantify uncertainty. That said, if you don’t want to do this “manually” like a pleb (which I did for our deskmate paper), or if you prefer a frequentist approach, the marginaleffects package got your back either way–it can work with brms but also with pretty much anything else (including lme4, nlme, and survey).
But wait, there’s more
This whole idea–predict values for certain combinations of predictors, contrast them, aggregate them–is extremely flexible. For example, instead of aggregating the individual causal effects across the whole sample, you could aggregate it for certain subgroups that may be of interest. Or you could use predictions to figure out what the average marginal effect would be like if all observations had a certain property. For example, in our paper, we looked at the average effect of being seated next to each other for different degrees of similarity between students, and we will return to that for the last example. You could even go wild and try to calculate average causal effects in a different population, which obviously only works well under certain assumptions but neatly links to the topic of generalizability and transportability.
Also, nobody forces you to aggregate across observations in the first case. You may want to calculate a marginal effect for a particularly representative observation, or maybe for your uncle Bob. You could even, please bear with me, generate some hypothetical “average observation”–an observation where all covariates are exactly at the sample mean–and estimate the causal effect for this particular observation. Now this particular observation may not actually exist in your data, and the effect for this average observation, called the marginal effect at the mean, may or may not be a good approximation of the average effect across observations, the average marginal effect. In some models, the two will coincide. Why would the marginal effect at the mean warrant special attention? Actually, its logic is closely tied to how psychologists sometimes calculate certain marginal effects, maybe even inadvertently, by implementing specific coding schemes.
Centering predictors prior to calculating the product term
Imagine a linear regression in which you want to predict some continuous outcome from two variables, X1 and X2, as well as their product, X1*X2. In such scenarios, it is routinely recommended that researchers center X1 and X2 prior to calculating the product term. You might have heard that this is helpful because it reduces multicollinearity, which is good, because multicollinearity is supposedly bad. Now leaving aside that collinearity isn’t a disease that needs curing, centering the predictors before calculating the product term won’t really change anything about your statistical model. It will still return precisely the same predictions for every single observation, and the uncertainty in those predictions will be unchanged, and so whatever marginal effect you calculate, the answer will be exactly the same.
But what does change is the magnitude of your regression coefficients, and how you can interpret them. Your regression equation looks something like this: Y = b0 + b1*X1 + b2*X2 + b3*X1*X2 + E. Without centering predictors, b1 will be the effect of a 1-unit change in X1 when X2 equals 0. Because if X2 is zero, the product term X1*X2 is zero as well, so we can safely ignore b3 to evaluate the effect of X1. If X2 is a variable where the value 0 is not of particular interest, or even completely implausible (say, if we’re talking about body height in centimeters), this hypothetical effect of X1 won’t be very interesting, even if it is compatible with our model.
When we do center the predictors, b1 will still be the effect of a 1-unit change in X1 when X2 equals 0. But after centering, X2 will be zero when it’s at the sample mean. So now b1 actually turns into the marginal effect at the mean. That is, in many cases, much more interpretable than the marginal effect at X2 = 0. Of course, even without centering, we could have calculated the marginal effect at the mean after estimating the model and arrive at the same answer, albeit in a second step.
Dummy coding, effect coding
Let’s imagine a different scenario in which we want to use a linear regression to predict some continuous outcome from two factors, A and B, with two levels each, as well as their interaction. Okay, to be honest, this is not exactly a different scenario–it’s a special case of the previous scenario, in which X1 and X2 are dichotomous. But, in psychology, there is a dedicated section of the methods training for experimental designs that is all about ANOVAs, and tends to use different letters. Actually, let’s just stick with X1 and X2, so that we can keep b for the regression coefficients without getting all confused about it. So, let’s imagine the same scenario as above, but X1 and X2 can only take on two possible values, and those represent different experimental conditions–we have a traditional 2×2 design.
We could use dummy coding, so that both X1 and X2 can take on the values 0 and 1. Our regression equation, as before, looks like this: Y = b0 + b1*X1 + b2*X2 + b3*X1*X2 + E. Just like above, b1 will be the effect of a 1-unit change in X1 when X2 equals 0. Here, X2 = 0 just happens to be the experimental condition that we coded that way. So b1 is the effect of X1 in one particular condition, the marginal effect of X1 for X2 = 0. In ANOVA speech, that is also called a simple effect.
But instead, we could also use effect coding. For example, we could code both variables so that they can take on the values -0.5 and +0.5. Again, Y = b0 + b1*X1 + b2*X2 + b3*X1*X2 + E and b1 will be the effect of a 1-unit change in X1 when X2 equals 0. But now X2 actually never equals 0 in the data! Zero is in the middle between the two possible values, -0.5 and +0.5. As a consequence, b1 will be precisely in the middle between the effect of X1 in the condition X2 = -0.5 and the effect of X1 in the condition X2 = +0.5, so it’s the mean of the two simple effects. If our design happens to be balanced (same number of people in all conditions, the platonic ideal of experimental research), this happens to be the marginal effect at the mean (and the average marginal effect, for that matter).
Specific vs. General Solutions
Those coding tricks are neat once you understand how they work. They are also quite limited in what they can achieve–you always have to recode your data to get a different marginal effect; the types of marginal effects you can get are limited; and anything you estimate will be on the same scale as your regression coefficients. The latter is no problem as long as you do linear regression, where the scale of the regression coefficients is the scale of the outcome (aka “identity link function”). But it becomes a pretty big topic whenever you use a non-linear model, so for our last example, let’s return to the deskmate experiment.
Example 4: Are you a boy dyad or a girl dyad?
In our paper on whether deskmates become friends, we were also interested in whether being seated next to each other “worked” better for some pairs of students than for others. In particular, it seemed plausible that this would most likely lead to friendship among students who are similar (and thus likely to befriend each other anyway). The kids in the study were in 3rd to 8th class, so one particularly salient dimension is gender. If you assign a girl to sit next to a boy (yuck!), is there still a chance they become friends?
To realize this on a statistical level, we used the same model as above, but additionally included a categorical variable indicating the gender of both students (three possible levels: both girls, one girl one boy, both boys) as well as its product with the binary deskmate variable into our probit model. If we look at the model-implied probit regression coefficients for each group, it does not look like our hypothesis pans out. For two girls, the deskmate effect is 0.27, for mixed dyads it’s 0.40, and for two boys it’s 0.39. This may look like the mixed dyads actually have the biggest effect of the intervention, although if we take into account uncertainty in those estimates, we might as well conclude that nothing happens at all with respect to effect moderation—the effects appear to be statistically indistinguishable.
But those regression coefficients need to be interpreted on the scale “latent continuous dimension underlying the probit model”, and that’s a bit abstract. So what does the model predict with respects to the actual outcome, (manifest) friendships? To answer this question, we can calculate average marginal effects for different types of dyads, by following the prediction procedure described above repeatedly, each time fixing the categorical variable indicating gender to a different value. Thus, we look at the average marginal effects if all our student pairs were all boys, all girls, or mixed.
If we follow that procedure and look at the increase in friendship probability, it is actually tiny for mixed dyads, and much bigger for same-gender dyads. So, if we do seat a boy next to a girl, the effect on their friendship probability is, on average, tiny in terms of percentage points (see Figure 7, which also shows the margins). This pattern is somewhat predictable if you know the different baseline probabilities of a friendship, the effects according to the regression coefficients and how the probit link works, but then again everything is obvious once you know the answer.
Figure 7
Model-implied friendship probabilities for pairs of students depending on their gender and the resulting effects of sitting next to each other.

So here we have a case where calculating marginal effects on the actual outcome scale results in qualitatively different conclusions than simply intently staring at regression coefficients. This is one example of interactions being scale dependent; this property can be interpreted quite broadly to think about, for example, ceiling and floor effects–for this additional plot twist, check out our manuscript on issues with interactions.
Marginal Gains
And that’s pretty much it. You pick your statistical model, estimate the parameters, use it to crank out predictions, contrast the predictions you want to contrast, aggregate whichever way you want to. This is a very flexible all-purpose workflow; it doesn’t even discriminate between Frequentists and Bayesians. One possible “downside” is that you suddenly have to consider which effect estimate is actually relevant for your particular context, but of course that’s not a bug, it’s a feature. I’d predict that the marginal effect of caring more about marginal effects would be an increase in the manifest number of average marginal effects in the literature.
That said, of course, I haven’t really told you anything about how to figure out which marginal effect you are interested in. Do you even want to know the average marginal effect? It definitely makes sense if you think about rolling out an actual intervention and want to gauge its impact overall. But in other scenarios, a group specific marginal effect may make more sense. Or maybe you want to illustrate what your models says for a number of observations that may represent particularly interesting observations, say, somebody with a median income, or somebody who is among the bottom or top 5% earners. Maybe there are even instances where, in a non-linear model, you do want to know what happens on the underlying latent scale rather than on the outcome scale. For example, Simonsohn seems to consider interactions on that latent scale substantively more interesting and calls them “conceptual interactions” (though there’s definitely people from other fields who would disagree with that assessment). The somewhat unsatisfying take-home message here could be that we often don’t know precisely what we want to estimate to begin with and might have to figure that out first. Though in any case, I believe it can’t hurt to provide multiple estimates to give a fuller picture of what the model says.
More generally, I believe that marginal effects are a good step towards a more productive understanding of statistical models. At least in psychology, we tend to teach them as special purpose tools–use a t-test if you want to compare two groups, ANOVA if you want to analyze factorial experiments, regression if you want to deal with continuous predictors[6]and use whatever is trending in your field for publishing in certain journals.–and students may consider themselves lucky if, at some point, somebody points out to them that they all belong to the same class of models. This makes stats appear much more arcane and fiddly than it needs to be. Instead, we could focus on teaching the general idea that statistical models are (fallible) predictions machines that can be queried in certain ways to answer certain questions.[7]I think there are some parallels here to Richard McElreath’s framing of statistical models as Golems, though I think Richard tends to care much more about how the golem is built. That seems like a useful framework to generate a general sense of familiarity, which we can then leverage to learn the nitty-gritty details in the next step, with less anxiety. In some contexts, it may still very much make sense to acquire a more mechanistic understanding of how particular models work, but this shouldn’t come at the expense of a more general understanding.
And now I’d recommend you get your hands dirty and estimate some marginal effects with the help of marginaleffects and some assistance by Andrew’s blog post.
Footnotes
| ↑1 | Can’t unsee Abbildung 2. |
|---|---|
| ↑2 | Who was so kind to comment on an earlier version of this blog post, for which I am very grateful. Of course, he bears no responsibility for any mistakes I made, let alone for any inappropriate joke. |
| ↑3 | Thus scooping the best English pun we could have come up with. Aber ich marg ihn trotzdem. |
| ↑4 | So don’t worry whether the trolley is accelerating toward anyone–in the vacuum of our thought experiment, nobody can hear them scream anyway. |
| ↑5 | If probit + fixed effects makes you wince (are you an economist by any chance?) we also did a variation that replaces classroom fixed effects with the size of the classroom. And a linear probability model, because we tried to make readers from all fields of the social sciences happy. |
| ↑6 | and use whatever is trending in your field for publishing in certain journals. |
| ↑7 | I think there are some parallels here to Richard McElreath’s framing of statistical models as Golems, though I think Richard tends to care much more about how the golem is built. |