
There have been persistent calls spurring psychologists to do more “idiographic” research, starting even before Peter Molenaar’s “Manifesto on Psychology as Idiographic Science”, which is already 20 years old. But now, finally, since a lot more psychologists are collecting the necessary intensive longitudinal data, the corresponding “idiographic” empirical papers are getting published.[1]Since publishing this blog post, I have been informed that people use the term “idiographic” in different ways, with some of the having quite strong opinions on what it entails and what it doesn’t. Moin Syed has a paper which discusses both the historical issues and the current use. For the present purposes, I’m happy to just run with “studies that use intensive longitudinal data and explicitly tout the advantages of their ‘idiographic approach’.” That seems to be just one possible flavor of idiographic research. Before they get published, they end up on the desks of skeptical and sometimes grumpy reviewers making a long face, such as me.
In principle, the idea of the idiographic approach is simple. Every human is different and thus none may be particularly well-described by averages. Knowing that the average life satisfaction of Germans is 6.72 scale points (according to OWID) does not tell you much about how happy I am (7.34 scale points, on Wednesdays). Knowing that involuntary job loss on average increases BMI by 0.1 kg/m2 (Marcus, 2014) doesn’t imply that that’s precisely how much you will gain. In fact, your weight may remain stable, or you may as well lose weight when the local chocolate factory kicks you out because you secretly looted the warehouse again. The possibility of heterogeneous causal effects is taken as a fact of life in the causal inference literature, with the acknowledgment that averages are often the best we can get.
People invested in an idiographic approach want more than that.[2]They do not want to saddle for averages. There is an alternative version of this blog post in which the horse puns don’t run out until the very end, courtesy of Malte. They do want to make statements about the individual. For example, how does personality change over age in a single individual and how much do these trajectories vary between people? What makes a person happy and to which extent do these factors vary between people? For the record, people who are perceived to be interested in the “nomothetic” side of things—insights that can be generalized to a larger population—are not per se uninterested in the individual-level causal effects. But they content themselves with statements about, for example, average causal effects of interventions. Maybe because they are aware that their data aren’t suited for inferences about individual level effects, or maybe because they are interested in applying said intervention to other people than the ones included in the study, in which case average causal effects are our best guess of what will happen.[3]For the connoisseurs of precision medicine and the like, calculating the average effect in a particular subgroup would still constitute a nomothetic approach as far as I can tell. The idiographic approach is really all about the individual observed in your study and not just about subgroups or moderators. Psychologists who test moderation hypothesis usually still hope for insights that are generalizable across people, such as “for people with M, X has an effect on Y.”
For most of the more “interesting” idiographic statements—for example, about within-person associations or individual-level effects—individuals need to be observed repeatedly. Researchers pursuing idiographic science are behooved supported by the technological revolution enabling experience sampling/ecological momentary assessment/ambulatory assessment/daily diaries, also known as smartphones. These make it easy to ping people and ask them to fill out questionnaires, even multiple times per day, resulting in so-called intensive longitudinal data.
In principle, that type of data is cool, and I respect people’s willingness to tackle hard research questions (such as those about individual-level causal effects), even if the willingness may partly be motivated by a lack of understanding for how hard these questions actually are. Interindividual differences in effects are per se an interesting phenomenon, and it’s not just psychologists who think so. For example, there are the promises of precision medicine and attempts to identify heterogeneity in response to treatments (such as fentanyl for breakthrough cancer pain) with the help of crossover trials (i.e., within-subject experiments).[4]Maybe somewhat unsurprisingly, that literature comes with its own methods problems. For example, researchers will calculate pre-post change scores in randomized controlled trials and then declare effect heterogeneity because these scores vary. This is not how response heterogeneity works; pre-post differences are not estimates of causal effects. If they were, there would be no need for a control group. It should also be noted that these people are very much interested in insights that are generalizable across people, such as finding ways to predict which treatment works for whom, so the motivation is not inherently idiographic. Reliably quantifying interindividual differences in effects is just a first step to identify treatments for which such a targeted approach may be feasible in the first place. There is also cool work on N-of-1 trials and the underlying causal framework which really makes me want to start more rigorous self-experimentation.
At the same time, many “idiographically motivated” papers I have seen in psychology have left me quite unimpressed for three mane main reasons. First, some of them fail to convincingly establish that the metric of interest varies between individuals in the first place. Second, even if such variation has been established, it often remains highly questionable whether we can make precise statements about any particular individual—which would be a precondition for making productive use of interindividual variation. Third, many studies seem quite confused about what precisely they are trying to do—claiming to be all about “within-person associations” which supposedly are not meant to be interpreted as causal claims but somehow still are meant to “elucidate intraindividual processes”, whatever those are. This problem is by no means unique to idiographic research, but it is quite pronounced, probably because such research relies on longitudinal data and psychological researchers seem somewhat confused about how longitudinal data and causal inference relate, which often results in unrealistic expectations.
More generally, none of these issues are specific to idiographic approaches. But in my experience, it’s not trivial to move from a general understanding (“Observed variability can be random”, “Estimates need error bars”, “Estimands matter”) to specific instances, in particular if the specific instances are Rube-Goldberg-type analyses one has not encountered before. Also, according to Aidan Wright, all three issues are pretty well-known in the idiographic modeling literature. I’m absolutely willing to believe that but as usual, things that are extensively discussed among the more technical crowd don’t always make their way to applied researchers.

Not all that varies is meaningful variation
Imagine you sampled people in two cities, 30 in each place. You collect data on their anxiety and depression and calculate the association between the two constructs. In the first city, you find b = 0.20 (a one-point increase in anxiety predicts a 0.2 point increase in depression) and in the second one b = 0.40 (a one-point increase in anxiety predicts a 0.40 point increase in depression). Should you conclude that in one of the cities, depression and anxiety are less strongly connected than in the other one?
You probably shouldn’t because with a sample size like that, associations are going to bounce around quite a bit and so if you collect data from an additional 30 people per city, the associations may look quite differently. Maybe now the association is actually stronger in the first city, or maybe they suddenly look more similar. The initial observation of b = 0.20 and b = 0.40 is still fully compatible with the idea that the underlying correlations are actually the same and the values in your study differ simply because of random sampling error.
Now let’s imagine you did the same but the two cities are instead two people which you repeatedly sample over a couple of days until you have 30 data points for each. Again, observing a stronger association in one of them than in the other one probably doesn’t tell you much, and to avoid foaling fooling yourself, it would be wise to first check whether the data are compatible with some null model in which the association between two constructs is actually the same for everyone.
If you harness a multilevel framework to analyze your data, with random slopes to reflect differences in the association, this check happens “automatically”: your model will estimate the standard deviation of the random slopes. If that standard deviation is negligible, you might as well stick with the simpler model in which the association is the same for everyone.[5]Reporting the standard deviation of the slope and its uncertainty is just a starting point. Matti Vuorre, Matthew Kay, and Niall Bolger have a very nice resource on communicating causal effect heterogeneity in Bayesian multilevel models. If you don’t like the whole random effects thing, you can also set up a fixed effects model in which the categorical predictor “participant ID” interacts with anxiety to predict depression. You can then check whether the model with the interaction actually significantly outperforms the model without it, the idea is the same – do we need to assume differences in the association between people to account for the data we observed? That approach is called fixed effects, individual slopes, and if you haven’t seen it yet, it’s probably because psychologists in general somehow don’t use traditional fixed effects models.
Using a multilevel or fixed effects model means that you’re still estimating one model including everyone. In the logic of the idiographic approach (explained in quite some detail in Kuper et al., in press), it may make more sense to actually run a separate model (possibly statistically sophisticated ones) for every single individual in the data. One may even allow for completely different models for each individual. For these procedures, it is not quite as trivial to establish that the associations actually vary beyond just random sampling error.
The most general way to check involves (repeatedly) simulating data under a null model—what would the data look like if there’s an association of realistic magnitude, but it’s the same for everyone?—and conducting the full analysis pipeline that you want to run on your real data. If the results on the simulated data would lead you to conclude that there’s interesting interindividual variation, you know that your approach is overeager to claim interindividual variation—because in your simulated data, no such variation exists, it’s all just sampling error. A variation of this idea are permutation tests, in which you start from the data you actually collected, but scramble it so that it has the same properties that you would desire from a null model (for example, an association between the constructs, but it’s the same for everyone).
Admittedly, running these checks isn’t trivial. If you’re the one who has to run them, I’m sorry, but that’s just the price that comes with doing more complex modeling. I’m more concerned about reviewers who may have to check such analyses with potentially little prior exposure to the approaches used. Authors may present something that seems quite compelling but actually doesn’t ensure sampling error isn’t mistaken for interindividual variation. Finding out how the presented analyses would behave in certain scenarios is anything but trivial and may require additional simulations. Now I assume reviewers usually aren’t motivated to dive deeper into the methods of a paper than the original authors did (the rare exception being my co-blogger Ruben), so to some degree they will have to rely on intuition here. What would we expect as a result of these analyses if there was no interesting idiographic variation?
For example, I reviewed a paper in which the authors categorized people depending on some feature of their idiographic model (effects from A to B, from B to A, neither or both), ignoring any sort of uncertainty in those models during the categorization. Across analyses, people were almost perfectly evenly distributed across the various categories. That seemed sus to me; substantively, not all categories were equally plausible. However, in this instance, such a pattern seemed plausible if the “idiographic variation” was in fact “mostly noise”, because noise can go either way. But setting up a model to prove that intuition would probably be a lot of effort and definitely not the job of a reviewer.
Just because we know something varies doesn’t mean we know much about any individual
Now imagine it was actually established that there’s meaningful variation between people. It’s still entirely possible that you cannot make precise statements about any individual in your data. In many contexts, that usually isn’t taken as a problem. But it does become a problem if “we are making statements about individuals instead of averages” is a central part of your spiel: Those statements may end up extremely uncertain, to the point of being mostly useless on the individual level. For example, authors may highlight as a unique benefit of their approach that it could be used to provide personalized advice, but if estimates end up being extremely uncertain, that advice won’t be better than just taking the average to inform advice. It could even be worse than the average. Imagine being told to lay off chocolate because it appears to make you unhappy based on 30 observations, even though there is great evidence from randomized controlled trials that chocolate increases happiness with an average treatment effect of 1.52 points per bar (in humans).
We encountered such a situation (minus the chocolate) in a recent project which resulted in the paper (title spoiler warning) “The Effects of Satisfaction With Different Domains of Life on General Life Satisfaction Vary Between Individuals (but We Cannot Tell You Why)”. We were interested in the effects of domain satisfaction (e.g., satisfaction with your social life) on overall life satisfaction and how much they varied between people. We found clear signs of interindividual differences of the non-sampling-error-type. But, for each individual, our estimate of whether their social life satisfaction had a bigger or a smaller impact on their general satisfaction was extremely noisy. The 95% credible intervals for the individual effects looked like this:
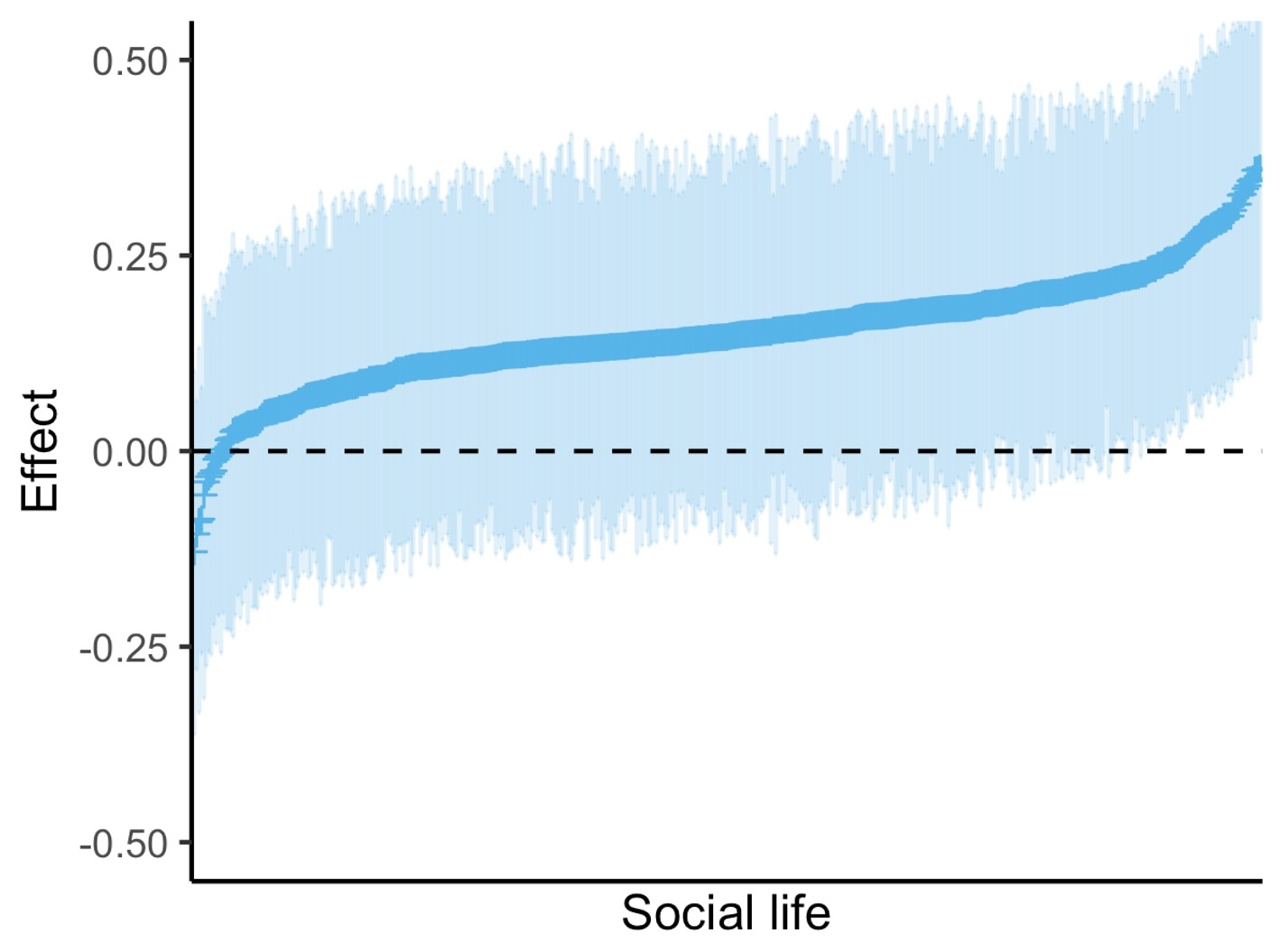
For most people, our point estimates fall somewhere between 0 and 0.25 points of overall life satisfaction per point in social life satisfaction; for each individual, we’re quite uncertain about the precise magnitude of the effect. Another way to communicate the uncertainty here is to calculate the reliability for our estimate of the individual-level effect. That turns out to be an abysmal 0.28; for reference, usually values exceeding 0.70 are deemed okay/adequate/good. We absolutely wouldn’t accept such a low reliability for a test that is supposed to meaningfully guide individual decision making. If we do want to make inferences across individuals—say, check whether the effects correlate with some personality variable—we may get away with such low reliabilities if we make up for it by sampling a lot more people.[6]We didn’t get away with it in this particular study because our data contained only 439 people; that’s simply not enough to make reliable statements about correlations between the (noisily measured) individual effects and third variables. But if we truly want to make inferences about individuals, we simply need to collect more data points per person. The discussion in our paper includes some back-of-the-envelope calculation which leads to the conclusion that even if we had collected four times as many data points per person (60 instead of only 15), reliability still wouldn’t have been great but at least okay-ish (>.60). Of course, that insight in itself may be helpful for potential future applications. And for me personally, it is definitely helpful for the planning of future studies. I now consider most attempts of modeling interindividual differences in effects based on “few” measurement occasions (including all annual panel data) mostly doomed.[7]For a more precise and less vibes-based assessment of feasibility, Aidan Wright, Florian Scharf and Johannes Zimmermann have a preprint in which they simulated how many assessments are needed to reliably estimate individual means, standard deviations and correlations in various scenarios.
Idiographic ≠ causal
The idiographic literature is filled with talk about “within-person processes”, “intraindividual dynamics”, and “lagged within-person effects.” These expressions are sufficient to invoke causal vibes without ever explicitly making causal claims, which I find highly unsatisfying—it’s a way to get away with all the fun implications of causal effects (Theorizing! Policy recommendations! Individualized therapy!) without all the trouble of actually figuring out how to plausibly achieve causal identification of the estimates. It also provides a comfortable amount of strategic ambiguity to shield one from criticism. This style is not unique to the idiographic literature—we have written about it as a more general phenomenon in nonexperimental psychology in Grosz et al., 2020—but it’s particularly pronounced there because it involves longitudinal data, and somehow psychologists have grown accustomed to the idea that longitudinal data solve all causal inference problems. They don’t, sorry. Within-person associations can still be confounded.
At this point, I hope we can all agree that some (likely hard to interpret) conditional association is not the actual thing we are theoretically interested in. We are interested in causal effects; it’s just hard to make confident statements about them, in particular without randomization. An underlying sentiment that I get from some parts of the literature is that if we just non-causal hard enough, at some point a causal understanding will arise. Just one more lagged effect that is not meant to be interpreted causally bro. One more lagged effect will fix it.
I consider this take fundamentally confused because we already know how to move from data (possibly observational, likely messy) to an understanding of what’s going on causally. It’s called causal inference, and there’s a whole literature on it. Is it easy? No. Does it provide any guarantees? Neigh. Is it likely to result in accurate answers? In many cases, probably not. But it’s still our best shot at finding out what’s going on causally, and it’s a lot more transparent and accountable than just presenting some numbers and wiggling your eyebrows suggestively.
A better way is to (1) spelling out the actual estimand of interest in precise terms and (2) listing and discussing central identification assumptions. If you want to see an example of what that could look like, check out our study on the effects of domain satisfaction on life satisfaction already mentioned above. The method section contains a whole subsection titled “Causal Identification Assumptions of the Individual Effects” and the general discussion contains a section titled “Potential Threats to Causal Identification.” What we wrote is by no means perfect, but I think it can serve as a proof of concept: It is absolutely possible to include such sections to be transparent about both analysis goals and limitations, at least at a progressive journal such as Collabra.[8]❤️
So you want to review an idiographic paper
(Or at least you feel obliged to do so)
It seems likely that we will see more papers implementing an idiographic approach in the future. As is bound to happen when a statistically and conceptually challenging approach becomes more popular, some of these will be quite bad, and some will make claims that are just not supported by the data presented. One way to ensure that the literature that comes out at the end is high quality is critical peer-review. But many reviewers won’t have much experience with idiographic methods, and it seems to me that many idiographic papers make up their own methods on the spot, making it even harder to assess whether conclusions are ultimately justified. So, to conclude this post with something hopefully useful, here are some questions that might be included in a review:
- Sampling error: The authors present potentially interesting variability between people. However, I would like to see more convincing evidence that this variability is not just random sampling error.
- In case a multilevel model or something that could be done with a multilevel model happened: In particular, I would like to see to which extent modeling random slopes actually helps explain the outcome. Do they meaningfully improve model fit?
- In case the analyses involved individual models or some other not trivial multi-step procedure: Could the authors demonstrate that if there is no interindividual variation, their analysis approach correctly concludes that no such variation exists? Some simulations of what the data would look like under a “null model” (for example, the association takes on the same non-zero value for everyone) might be helpful. I would strongly recommend to include this in the main text because skeptical readers may wonder the same.
- Precision of the individual estimates: The authors demonstrate that [quantity] varies between individuals. One thing I was wondering: How confidently can they actually make statements about any individuals’ [quantity]? This seems important information, given that people may wonder about the practical implications of the findings presented. For example, do we know enough to hand out personalized recommendations? I could imagine different types of quantification here. For example, the authors’ could plot the [quantity] predicted for each individual, including some intervals quantifying the corresponding uncertainty. Alternatively or additionally, they may be able to provide an estimate of the reliability of the individual-level estimates of [quantity]. To be perfectly clear, a low precision of the individual estimates would not constitute a weakness of the authors’ work; it is just an important empirical result that may help others plan their studies accordingly.
- Causal inference: The authors state that they are interested in [include whatever ambiguous language the authors use to describe the association between X and Y]. I was wondering what precisely they mean by that. Is this meant to be interpreted as “merely” an association? If so, could the authors explicate the benefit of knowing said association, given that associations are of very limited use for practical application and theorizing (as theories are usually concerned with statements about how variables affect each other)? Alternatively, and this seems to be more compatible with the implications discussed later in the manuscript—maybe the authors are actually interested in the effect of X on Y? If this is the case, this should be articulated in clear language. Causal conclusions based on observational data require that certain assumptions are met, and I would like to ask the authors to spell out the necessary identification assumptions in the main body of the manuscript. If the authors feel like they need additional guidance for these steps, Lundberg et al. (2021: https://journals.sagepub.com/doi/full/10.1177/00031224211004187) provide a very nice and thorough introduction for how to spell out analysis goals. If questions arise regarding the role of longitudinal data for causal inference, Rohrer and Murayama (2023; https://journals.sagepub.com/doi/10.1177/25152459221140842) may be a helpful starting point to read up on the matter.

Acknowledgment: This blog post was significantly inspired and informed by a lively discussion with Niclas Kuper and Ruben. Neither of them bears any responsibility for the content of this blog post. Except maybe for Ruben, who as a co-blogger may be partially incriminated. Aidan Wright added some comments on Bluesky which led to some additional minor changes.
Footnotes
| ↑1 | Since publishing this blog post, I have been informed that people use the term “idiographic” in different ways, with some of the having quite strong opinions on what it entails and what it doesn’t. Moin Syed has a paper which discusses both the historical issues and the current use. For the present purposes, I’m happy to just run with “studies that use intensive longitudinal data and explicitly tout the advantages of their ‘idiographic approach’.” That seems to be just one possible flavor of idiographic research. |
|---|---|
| ↑2 | They do not want to saddle for averages. There is an alternative version of this blog post in which the horse puns don’t run out until the very end, courtesy of Malte. |
| ↑3 | For the connoisseurs of precision medicine and the like, calculating the average effect in a particular subgroup would still constitute a nomothetic approach as far as I can tell. The idiographic approach is really all about the individual observed in your study and not just about subgroups or moderators. Psychologists who test moderation hypothesis usually still hope for insights that are generalizable across people, such as “for people with M, X has an effect on Y.” |
| ↑4 | Maybe somewhat unsurprisingly, that literature comes with its own methods problems. For example, researchers will calculate pre-post change scores in randomized controlled trials and then declare effect heterogeneity because these scores vary. This is not how response heterogeneity works; pre-post differences are not estimates of causal effects. If they were, there would be no need for a control group. It should also be noted that these people are very much interested in insights that are generalizable across people, such as finding ways to predict which treatment works for whom, so the motivation is not inherently idiographic. Reliably quantifying interindividual differences in effects is just a first step to identify treatments for which such a targeted approach may be feasible in the first place. |
| ↑5 | Reporting the standard deviation of the slope and its uncertainty is just a starting point. Matti Vuorre, Matthew Kay, and Niall Bolger have a very nice resource on communicating causal effect heterogeneity in Bayesian multilevel models. |
| ↑6 | We didn’t get away with it in this particular study because our data contained only 439 people; that’s simply not enough to make reliable statements about correlations between the (noisily measured) individual effects and third variables. |
| ↑7 | For a more precise and less vibes-based assessment of feasibility, Aidan Wright, Florian Scharf and Johannes Zimmermann have a preprint in which they simulated how many assessments are needed to reliably estimate individual means, standard deviations and correlations in various scenarios. |
| ↑8 | ❤️ |