
In the current system of pre-publication peer review, which papers are scrutinized most thoroughly? In this blog post, I argue that scrutiny is mis-allocated: the average number of pre-publication reviews (and reviewer effort) a manuscript has accumulated by the time it is published is lower for papers published very visibly (e.g., in high-impact journals).
Why? Consider this: most authors gamble and submit their manuscript to the highest-ranked journal (by whichever metric) where they think it stands a fighting chance. Acceptance rates at these journals are necessarily low, so many papers are rejected there and submitted elsewhere, where they receive new reviews. If authors facing rejection go down their list of potential journals and the manuscript receives reviews at some of them, the papers that end up published in lower-rung journals have left a trail of reviews at higher-rung journals. By comparison, those papers that end up at the author’s first choice get only the reviews (perhaps for multiple revisions) at that journal.
Of course the highly visible papers then go on to be cited much more. This has some odd consequences. The cornerstones of our science, the claims we cite most, are examined relatively little prior to publication, whereas we spend many more person hours checking for faults in the bathroom tiles. Less grave, but still odd: If there is an association between quality and odds of acceptance at the first choice, and thus low quality manuscripts get sent out for review more frequently, this implies that the average paper you receive for review is worse than the average paper. I definitely feel that way, but always thought I was just unlucky.
I decided to run a quick simulation to check my intuition. The results are easily summarised in the following graph.
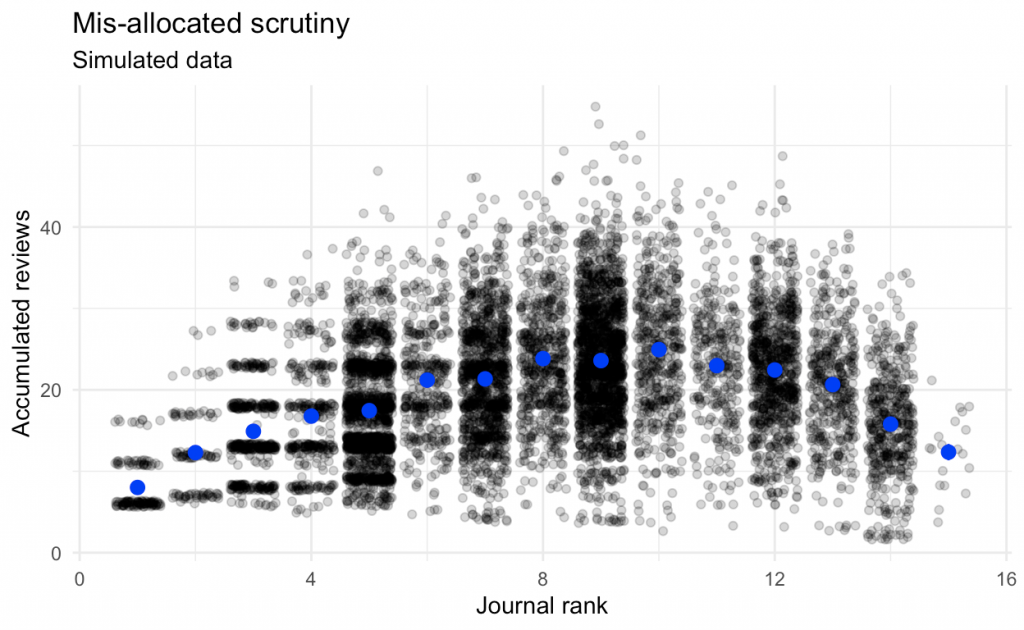
I made the following assumptions (the code is on my personal blog):
- I’m looking at a cohort of submitted papers and comparing their fates, not papers published in a given year (in truth, some papers will be more delayed by the review process than others, so at any point in time, the published papers will skew more to those that were less delayed in review, but I found it difficult to intuit which steps take longer)
- Papers have a certain “fitness”, which affects how likely they are to be submitted, desk rejected, sent for review, and whether the decision is reject, revise and resubmit or acceptance. (I expressly avoided the term “quality” here, because I doubt this is the only or even main ingredient in a paper’s fitness).
- Journals behave as follows
- they have a certain threshold for acceptance, which is noisily linked to their fame, which entirely determines their rank
- higher-ranked journals recruit more reviewers (between 1 and 5)[1]I’m unsure how true that actually is, probably the more crucial factors are the editor’s prerogative and whether an unexpected number of reviewers say yes to a review request. But maybe reviewers try harder at top journals, so we can let the number of reviewers stand in for that.
- when we have more reviewers, we get a better decision on the manuscript’s fit (i.e. higher-ranked journals make fewer mistakes when judging a manuscript against their threshold)[2]of course, pessimists might also say that more reviewers just means more opinions, and that busy editors do not actually extract more signal from many noisy reviews
- editorial review counts as one review, so desk rejections modestly contribute to the review tally even though these rarely lead to long written reviews.
- reviews of revisions count as full reviews (this probably overestimates the additional effort that goes into reviews of revisions compared to novel submissions)
- Authors behave as follows:
- they submit their paper to the highest-rung journal where they think it stands a chance (journals whose fame is no more than 2.5 SDs above the manuscript’s fitness)
- if they get desk rejected, they make a minimal effort to improve the manuscript’s fitness (with diminishing returns after repeated rejections)
- if they get rejected after reviews, they make a slightly bigger effort to improve the manuscript’s fitness (again, with diminishing returns)
- if they get a revise and resubmit decision, they make the most effort to improve the manuscript’s fitness (but again, with diminishing returns depending on how often they have submitted the paper already).
- if the manuscript is rejected, they submit it to the next journal on their list. They give up after 10 submissions.[3]this is probably conservative and discouraged authors probably often skip a few rungs on the ladder, which I also did not model
As you will note, many of the decisions in this simulation reflect an effort on my part to make the negative correlation between number of reviews and journal fame less of a foregone conclusion.[4]Certainly, one could improve the simulation’s realism further and explore it over a range of parameter values, but I’m only procrastinating checking the table numbers of my supplement, not submitting my PhD thesis, what do you expect from me? That said, if anyone knows a source for some empirical data on this relationship, let me know! And if you want to read something solid on a related topic, I strongly recommend Tiokhin et al., who also review much related literature and Brembs et al. who go through many other bad consequences of journal rank.
Some practices such as taking your reviews with you (streamlined review), or getting a recommendation for a much-lower-rung sister journal after rejection, are probably intended to somewhat reduce the number of times rejected manuscripts get re-reviewed.
But what about the other side of the coin, increasing scrutiny for papers accepted in top journals? Higher-impact journals sometimes recruit more reviewers, who might exert more effort. These journals also occasionally have statistical editors or require more transparency — but that’s so rare it hardly merits a mention. In any case, these measures clearly do not prevent errors from slipping through. Post-publication reviewers routinely notice errors in and problems with papers published in high-impact journals, but often only after these have already made a big splash, been cited a lot, yielded book deals, or even influenced policy. Depending on how discerning journals are for research quality and how much peer review actually improves manuscripts and corrects errors, we might end up surprised by how little research quality can be predicted by the journal’s IF.
Now, whether we think this is good or bad depends on a few things. The Move fast and break things attitude could work well if we made sure that uncertainty propagates, i.e. that novel claims relying on published uncertain claims take that uncertainty into account. We would release claims quickly, let the wisdom of crowds sort out which are interesting and make sure the amount of scrutiny tracks the level of interest in a claim. Unfortunately, I haven’t seen much evidence that suggests we’re good at uncertainty propagation, or even at correcting studies based on completely erroneous claims. Instead, studies become stylised facts that long outlive the original paper. In our old-fashioned publication system, retracted claims and non-replicated studies keep getting cited, so even claims that were corrected post-publication continue to cause harm down the (citation) line.[5]As an anecdote, check out the number of citations Diederik Stapel’s retracted articles continue to rack up. The other approach would be predicting the level of interest before publication and trying to match the amount of scrutiny to it. This too might be difficult—papers at high-rank journals, which try to select studies which will be cited a lot, still vary a lot in the amount of attention they end up receiving.[6]In addition, it seems unthinkable that a paper will get a hundred pre-publication reviews. But for scientific news that are seen as truly groundbreaking, go around the world, and influence policy, that might be the appropriate level of scrutiny. And, of course, papers may receive less attention than deserved because they end up in low-rank journals.
I’m tempted to hope that we can improve our “dependency management system”, i.e. how far errors are passed down the citation line. In an ideal world, finding that a claim in a published paper was refuted or even just weakened would lead to an update in all documents and discussions that have cited the claim and those that cited those documents in turn. Slightly less utopian, but still pretty utopian, progress could be made by treating studies that have only been reviewed by a handful of people behind closed doors more skeptically, getting people to write more post-publication peer reviews, checking code and data for reproducibility, and running replications. It’s a tall order, but easier than correctly predicting which claims will be found interesting, a task which people have long tried to optimise for. In some cases, this process is even fast enough for the correction to appear in the same news cycle as the original message. [7]For the sake of completeness: In the dystopian approach, a sentient AI trained purely on Nick Brown’s blog evaluates each and every academic paper on PubPeer, whereas in the Aesopian system, studies with known flaws are referred to in brutally denigrating, yet highly codified language that appears perfectly reasonable and polite to the uninitiated (e.g., “exploratory research”).
I’ve seen people express worry that moving to a post-publication peer review system would lead to a world where only papers that are highly visible would get reviews.
I say let’s go for it, it’s at least better than spending most of our time scrutinising the bottom of the barrel.
Footnotes
| ↑1 | I’m unsure how true that actually is, probably the more crucial factors are the editor’s prerogative and whether an unexpected number of reviewers say yes to a review request. But maybe reviewers try harder at top journals, so we can let the number of reviewers stand in for that. |
|---|---|
| ↑2 | of course, pessimists might also say that more reviewers just means more opinions, and that busy editors do not actually extract more signal from many noisy reviews |
| ↑3 | this is probably conservative and discouraged authors probably often skip a few rungs on the ladder, which I also did not model |
| ↑4 | Certainly, one could improve the simulation’s realism further and explore it over a range of parameter values, but I’m only procrastinating checking the table numbers of my supplement, not submitting my PhD thesis, what do you expect from me? That said, if anyone knows a source for some empirical data on this relationship, let me know! And if you want to read something solid on a related topic, I strongly recommend Tiokhin et al., who also review much related literature and Brembs et al. who go through many other bad consequences of journal rank. |
| ↑5 | As an anecdote, check out the number of citations Diederik Stapel’s retracted articles continue to rack up. |
| ↑6 | In addition, it seems unthinkable that a paper will get a hundred pre-publication reviews. But for scientific news that are seen as truly groundbreaking, go around the world, and influence policy, that might be the appropriate level of scrutiny. |
| ↑7 | For the sake of completeness: In the dystopian approach, a sentient AI trained purely on Nick Brown’s blog evaluates each and every academic paper on PubPeer, whereas in the Aesopian system, studies with known flaws are referred to in brutally denigrating, yet highly codified language that appears perfectly reasonable and polite to the uninitiated (e.g., “exploratory research”). |